本文知识来自C++ Concurrency In Action,介绍无锁数据结构的设计。介于个人理解能力有限,本文并不保证所有内容都是正确的,建议对照原文进行理解。
本文结构
无锁数据结构概述
mutex是确保多线程可以安全的访问数据,而没有条件竞争(race condition)和破坏的不变量(一个线程在写,另一个线程看到了在写过程中的状态)的强有力工具。使用它也是相对比较直接的:该段代码是否需要保护。当然它也不是没有缺点的,不正确的使用可能会导致死锁(dead lock)。如果你能写出能够安全并发且无锁的数据结构出来,那么潜在意义上就避免了这个问题,这样的数据结构称为“无锁数据结构”。
无锁数据结构的设计必须小心又小心,因为一些导致失败的条件可能很少发生。
使用mutex、condition variable或future进行数据同步的算法或数据结构被称为阻塞式算法或数据结构,不使用阻塞式函数的算法或数据结构被称为非阻塞算法或数据结构。
并不是所有的非阻塞式数据结构都是无锁的。
如果一个数据结构被称为无锁的,那么多个线程一定可以并发的访问该数据结构。这些线程不需要做相同的操作,一个无锁的queue可能允许一个线程push,另一个线程pop,甚至在两个线程同时push时造成中断;不仅如此,当一个线程被调度器中途挂起时,另外的线程仍然可以继续完成它的操作而不用等待这个被挂起的线程。
compare/exchange操作经常被用在循环里面,之所以用compare/exchange操作是因为其它线程可能同时对数据做了更改,因此需要在重新调用compare/exchange操作前重新做一系列操作,这样的代码在那些修改数据的线程被挂起并操作成功时也可以是无锁的,否则就是非阻塞但非无锁的。具有这种循环的无锁算法可能导致一个线程遭受饥饿:如果另一个线程使用“错误”时序执行操作,则另一个线程可能会在第一个线程不断重试其操作时进行。避免这种问题的数据结构是无等待的,也是无锁的。
Lock-free algorithms with such loops can result in one thread being subject to starvation. If another thread performs operations with the “wrong” timing, the other thread might make progress while the first thread continually has to retry its operation. Data structures that avoid this problem are wait-free as well as lock-free.
无等待数据结构是一个无锁的数据结构,其附加属性是访问数据结构的每个线程都可以在有限数量的步骤中完成其操作,而不管其他线程的行为如何,因为与其他线程冲突而涉及无限次重试的算法因此不会等待。正确书写无等待数据结构时非常非常困难的:为了确保每个线程都能在有限数量的步骤中完成其操作,你必须确保每个操作都可以在单次执行中执行,并且一个线程执行的步骤不会导致另一个线程上的操作失败。
由于正确的获得一个无锁或无等待的数据结构的困难性,你必须确保得到的好处超过了成本:
- 使用无锁数据结构的最主要原因是获得最大的并发性能,使用无锁数据结构时,每个线程都能向前进而不管其它线程在做什么,也不需要等待,这样的功能谁都想要,但是却很难实现;
- 使用无锁数据结构的第二个原因是鲁棒性(robustness),如果一个线程在持有锁时被销毁,那么这个数据结构就永远损坏了,但如果使用的是无锁数据结构,那么损坏的就只有那个线程的数据了,其他线程可以正常运行;
- 如果你不能排除其它线程访问数据结构,那么你就要小心维护不变量,为了避免条件竞争(race condition),你必须使用原子操作来修改数据,除此之外,你还必须确保修改以正确的顺序显示给其它线程;
- 因为没有锁,所以无锁数据结构不会造成dead lock,但是可能造成live lock:想象当两个线程都想要修改数据,但是任何一个线程所做的操作都会导致另一个线程的操作重新执行,所以两个线程会一直循环尝试。就像两个人同时从两边过一个独木桥,必须要一方通过之后,另一方才能继续通过。就定义上来讲,无等待数据结构是不会造成live lock的,因为它们执行操作的步骤总是有上限的,但换个角度讲,无等待算法要比等待算法复杂度高,且就算没有其它线程访问数据也会需要更多的步骤来完成对应操作。
- 尽管无锁或无等待数据结构可以增加并发操作的潜力,并减少线程花费等待的时间,但它可能会降低整体性能。因为原子操作可能比非原子操作慢得多,并且无锁数据结构的操作相对于使用锁的数据结构的操作要更多;不仅如此,硬件必须在访问相同原子变量的线程之间同步数据。
在介绍无锁数据结构设计之前,我们需要一些C++内存模型和原子操作的知识。
C++ 内存模型和原子操作
内存模型
C++ 程序中的所有数据都是由对象(object)构成,C++ 标准定义一个对象(object)为“存储区(memory location)”。
像int、float这样的对象(object)是简单基本类型;像array、自定义类型的对象会拥有子对象(数据成员)。不管一个对象是什么类型,它都会被存储在一个或多个存储区(memory location)里,每个存储区(memory location)里面存放着一个对象或子对象,如unsigned short或my_class*或相邻位位域(bit field)序列。
如果你使用位域(bit field),那么有一个重要的点你需要注意:虽然相邻位域都是不同的对象,它们仍被视为相同的存储区(memory location)。
对象、存储区与并发
C++ 多线程应用程序的关键部分:一切都取决于存储区(everything hinges on those memory locations)。
如果两个线程访问分离(separate)的存储区,一切都会工作的很好(everything works fine);如果两个线程访问相同(same)的存储区,你就要小心了:如果没有线程更新这个存储区(只读),那么没有问题;但如果两个线程都在修改数据,就会有条件竞争(race condition)的危险。
为了避免条件竞争(race condition),两个线程不得不按一定的顺序访问存储区,一种确保访问顺序的方法是使用std::mutex,另一种方法就是使用原子操作(atomic operation)。
如果两个线程没有按顺序访问相同的存储区,那么这两个访问中的一个或两个就不是原子(atomic)的,这会造成未定义行为(undefined behavior)。
原子操作并没有避免竞争本身,哪个原子操作先访问存储区仍然没有被指定,但是它将程序拉回了定义行为的区域内。
修改顺序(modification order)
一个C++ 程序中的每个对象从初始化开始,就拥有一个定义的修改顺序(modification order),用来限定程序中的所有线程对该对象的修改操作(Every object in a C++ program has a defined modification order composed of all the writes to that object from all threads in the program, starting with the object’s initialization)。
大多数情况下,这个修改顺序(modification order)在运行时会有所变化,但是在程序已经执行的情况下,所有线程都必须遵守这个顺序。如果一个对象不是原子类型(atomic type),你就要负责充分的同步,用于确保所有线程都遵守了每个变量的修改顺序(modification order),否则就会出现数据竞争(data race)和未定义行为(undefined behavior);如果该对象是原子类型,那么编译器就会帮你确保必要的同步。
虽然所有线程必须遵守每个对象的修改顺序,但是它们并没有必要遵守不同对象的相对顺序(Although all threads must agree on the modification orders of each individual object in a program, they don’t necessarily have to agree on the relative order of operations on separate objects)。
原子操作与原子类型
顾名思义,一个原子操作(atomic operation)是一个不可分割(indivisible)的操作。
一个原子操作的结果要么未完成,要么已完成(Y/N),你不能在一个原子操作进行一半的时候进行查看。如果对一个对象读值的操作是原子的,那么所有对该对象的修改操作都是原子的,因为读到的值要么是初始值,要么是已修改后的值。
这意味着一个非原子操作在进行一半的时候可能被另一个线程看到了,这就很大概率造成数据竞争(data race)和未定义行为(undefined behavior)。
在 C++ 里面,大多数情况下,你需要用一个原子类型去获取一个原子操作。
标准原子类型定义于头文件<atomic>中,对标准原子类型的所有操作都是原子的,且在C++定义中只有对标准原子类型的操作是原子的,虽然你可以使用std::mutex来达到原子操作的效果。
原子类型没有拷贝操作,几乎所有的原子类型都有一个成员函数is_lock_free()
- 如果该函数返回true,那么对该类型的操作直接以原子指令完成;
- 如果该函数返回false,那么对该类型的操作以使用对编译器和库的内部锁的形式完成。
唯一不提供is_lock_free()成员函数的类型是std::atomic_flag。这个类型是一个简单的布尔标志,该类型一定是无锁的(lock free)。剩下的原子类型全部都是模板std::atomic<>的特例化版本,它们比std::atomic_flag拥有更多的功能,但是可能不是无锁的(lock free)。
头文件<atomic>中定义了很多std::atomic<>模板特例化的别名(但是通常直接使用模板会比较方便),命名的格式很简单:
// ATOMIC TYPEDEFS
typedef atomic<bool> atomic_bool;
typedef atomic<char> atomic_char;
typedef atomic<signed char> atomic_schar;
typedef atomic<unsigned char> atomic_uchar;
typedef atomic<short> atomic_short;
typedef atomic<unsigned short> atomic_ushort;
typedef atomic<int> atomic_int;
typedef atomic<unsigned int> atomic_uint;
typedef atomic<long> atomic_long;
typedef atomic<unsigned long> atomic_ulong;
typedef atomic<long long> atomic_llong;
typedef atomic<unsigned long long> atomic_ullong;
typedef atomic<char16_t> atomic_char16_t;
typedef atomic<char32_t> atomic_char32_t;
typedef atomic<wchar_t> atomic_wchar_t;
typedef atomic<int8_t> atomic_int8_t;
typedef atomic<uint8_t> atomic_uint8_t;
typedef atomic<int16_t> atomic_int16_t;
typedef atomic<uint16_t> atomic_uint16_t;
typedef atomic<int32_t> atomic_int32_t;
typedef atomic<uint32_t> atomic_uint32_t;
typedef atomic<int64_t> atomic_int64_t;
typedef atomic<uint64_t> atomic_uint64_t;
typedef atomic<int_least8_t> atomic_int_least8_t;
typedef atomic<uint_least8_t> atomic_uint_least8_t;
typedef atomic<int_least16_t> atomic_int_least16_t;
typedef atomic<uint_least16_t> atomic_uint_least16_t;
typedef atomic<int_least32_t> atomic_int_least32_t;
typedef atomic<uint_least32_t> atomic_uint_least32_t;
typedef atomic<int_least64_t> atomic_int_least64_t;
typedef atomic<uint_least64_t> atomic_uint_least64_t;
typedef atomic<int_fast8_t> atomic_int_fast8_t;
typedef atomic<uint_fast8_t> atomic_uint_fast8_t;
typedef atomic<int_fast16_t> atomic_int_fast16_t;
typedef atomic<uint_fast16_t> atomic_uint_fast16_t;
typedef atomic<int_fast32_t> atomic_int_fast32_t;
typedef atomic<uint_fast32_t> atomic_uint_fast32_t;
typedef atomic<int_fast64_t> atomic_int_fast64_t;
typedef atomic<uint_fast64_t> atomic_uint_fast64_t;
typedef atomic<intptr_t> atomic_intptr_t;
typedef atomic<uintptr_t> atomic_uintptr_t;
typedef atomic<size_t> atomic_size_t;
typedef atomic<ptrdiff_t> atomic_ptrdiff_t;
typedef atomic<intmax_t> atomic_intmax_t;
typedef atomic<uintmax_t> atomic_uintmax_t;
你也可以使用自己的类型来特例化std::atomic<>模板。
每种原子类型的操作都有一个可选的内存顺序(memory order)参数,根据操作的类别,每种操作能使用的参数不尽相同,但所有操作的默认参数都是memory_order_seq_cst,这些参数的意义会在后面进行讲解:
- 储存操作(store operation):
memory_order_relaxed,memory_order_release,memory_order_seq_cst; - 加载操作(load operation):
memory_order_relaxed,memory_order_consume,memory_order_acquire,memory_order_seq_cst; - 读改写操作(read-modify-write):
memory_order_relaxed,memory_order_consume,memory_order_acquire,memory_order_release,memory_order_acq_rel,memory_order_seq_cst。
std::atomic_flag
std::atomic_flag是最简单的标准原子类型,它表示一个bool flag。
std::atomic_flag的对象只有两种状态:set、clear。这种类型几乎从没被使用过,除非在十分特别的情况下,但是它会展示一些原子类型的通用策略。
std::atomic_flag对象必须以ATOMIC_FLAG_INIT初始化,该初始化使得其状态设置为clear。
std::atomic_flag f = ATOMIC_FLAG_INIT;
std::atomic_flag是唯一需要以如此特别的方式初始化的原子类型,但它也是唯一保证无锁(lock free)的类型。
如果一个std::atomic_flag对象拥有静态存储期,那么它保证会被静态初始化,这意味着没有初始化顺序问题–对该对象的第一次操作会将其初始化。
一旦一个std::atomic_flag对象被初始化了,你只能对其做三件事:destroy、clear、set并查询前一个值,分别使用析构函数、clear()成员函数、test_and_set()成员函数。其中clear()是一个存储操作(store operation),test_and_set()是一个读改写操作(read-modify-write)。
同时对两个不同的对象进行的操作不可能是原子的,因为先要对一个对象进行操作,再对另一个对象进行操作,这样中间状态就可能被看到,所以原子操作都删除了拷贝操作(包括拷贝构造函数和拷贝赋值运算符)。
有限的特性使得std::atomic_flag非常适合用来做spinlock mutex(一种死等的锁机制),下面的实现是无阻塞但非无锁的,因为使用无锁数据结构时,每个线程都能向前进而不管其它线程在做什么,也不需要等待,很明显这里等待了:
// 一个使用std::atomic_flag的spinlock mutex实现
class spinlock_mutex
{
std::atomic_flag flag;
public:
spinlock_mutex() :
flag{ ATOMIC_FLAG_INIT }
{}
void lock()
{
// test_and_set: 将状态设置为set,即flag设置为true,返回前一个值
// 如果flag是clear状态,那么循环终止
// 如果flag是set状态,即该对象已经被lock了,就一直循环等待unlock
while (flag.test_and_set(std::memory_order_acquire));
}
void unlock()
{
flag.clear(std::memory_order_release);
}
};
atomic_bool
由于std::atomic_flag没有无修改查询操作,所以它甚至都不能当做一个通用的布尔标志来使用。
最基本的原子整形类型是std::atomic<bool>,它比std::atomic_flag拥有更多的特性,虽然它仍然没有拷贝操作,但是它可以使用非原子类型bool变量构造或赋值:
std::atomic<bool> b(true);
b = false;
查看std::atomic<>模板的源代码:
_ITYPE operator=(_ITYPE _Val) _NOEXCEPT
{ // assign from _Val
return (_ATOMIC_ITYPE::operator=(_Val));
}
发现其赋值运算符与常规的赋值运算符不太一样,常规的赋值运算符返回的都是引用,但是std::atomic<>模板的赋值运算符返回的却是一个值。如果返回的是一个引用,那么任何依赖赋值结果的代码就不得不在做一次获取值的操作,这样就可能获取到其它线程修改后的值,通过直接返回存储的非原子类型值,就可以避免这次获取值的操作。
与std::atomic_flag不同,std::atomic<bool>通过store()成员函数来写值,并且可以设置为true or false;通过exchange()来设置新值并返回前一个值;并且提供一个无修改查询函数load(),用以将对象隐式的转换为一个普通的bool值:
std::atomic<bool> b;
bool x = b.load(std::memory_order_acquire);
b.store(true);
x = b.exchange(false, std::memory_order_acq_rel);
一个新的操作叫做“比较/交换”(compare/exchange),它以成员函数compare_exchange_weak()和compare_exchange_strong()的形式表现出来。“比较/交换”(compare/exchange)操作是原子类型编程的基石,若期望值与实际值相等,则存储提供的值;若不等,则期望值将被更新为实际值。
“比较/交换”(compare/exchange)操作的返回值是一个bool值,若期望值与实际值相等则返回true,否则返回false。
bool compare_exchange_weak(_Ty& _Exp, _Ty _Value,
memory_order _Order1, memory_order _Order2) _NOEXCEPT
{ // compare and exchange value stored in *this with *_Exp, _Value
return (this->_Compare_exchange_weak(
(void *)_STD addressof(_My_val), (void *)_STD addressof(_Exp), (const void *)_STD addressof(_Value),
_Order1, _Order2));
}
bool _Compare_exchange_weak(
void *_Tgt, void *_Exp, const void *_Value,
memory_order _Order1, memory_order _Order2) volatile
{ // lock and compare/exchange
return (_Atomic_compare_exchange_weak(
&_My_flag, _Bytes, _Tgt, _Exp, _Value, _Order1, _Order2));
}
inline int _Atomic_compare_exchange_weak(
volatile _Atomic_flag_t *_Flag, size_t _Size,
volatile void *_Tgt, volatile void *_Exp, const volatile void *_Src,
memory_order, memory_order)
{ /* atomically compare and exchange with memory ordering */
int _Result;
_Lock_spin_lock(_Flag);
_Result = _CSTD memcmp((const void *)_Tgt, (const void *)_Exp, _Size) == 0;
if (_Result != 0)
_CSTD memcpy((void *)_Tgt, (void *)_Src, _Size);
else
_CSTD memcpy((void *)_Exp, (void *)_Tgt, _Size);
_Unlock_spin_lock(_Flag);
return (_Result);
}
compare_exchange_weak()的存储操作即使在期望值与实际值相等的情况下也可能不会成功,这使得实际值并没有改变,返回值也是false,这可能发生在缺少“比较/交换”(compare/exchange)指令的机器上。如果处理器不能保证该操作是原子的,就可能发生这种情况,这被称为伪失败(spurious failure),因为失败的原因不是变量的值。
由于compare_exchange_weak()可能发生伪失败(spurious failure),所以它通常被用在一个循环中:
bool expected = false;
extern std::atomic<bool> b; // set somewhere else
// 当发生伪失败时,就会继续循环,否则会退出循环
while (!b.compare_exchange_weak(expected, true) && !expected);
compare_exchange_strong()保证只有当期望值与实际值不等的情况下才返回false,这就可以消除上面的循环。
如果存储的值比较简单,那么使用compare_exchange_weak(),否则使用compare_exchange_strong()。
“比较/交换”(compare/exchange)操作接受两个内存顺序(memory order)参数,对应成功和失败两种情况。禁止提供memeory_order_release和memory_order_acq_rel给失败的情况;如果你想提供memory_order_acquire或memory_order_seq_cst给失败情况,那么你必须也提供给成功的情况。
如果你没有指定顺序给失败的情况,那么失败的顺序跟成功的顺序一样,除了release部分:memory_order_release会变成memory_order_relaxed,memory_order_acq_rel会变成memory_order_acquire。如果你两个都没有指定,那么默认为memory_order_seq_cst。
std::atomic<bool> b;
bool expected;
b.compare_exchange_weak(expected, true,
std::memory_order_acq_rel, std::memory_order_acquire);
// 跟上面等价
b.compare_exchange_weak(expected, true, std::memory_order_acq_rel);
std::atomic<bool>与std::atomic_flag的另一个不同是:std::atomic<bool>可能不是无锁的(lock free),其实现可能需要一个内部互斥锁,如上面查找的源码所示。你可以使用is_lock_free()成员函数来确认是否是lock free的。
atomic_pointer
指针的原子形式是std::atomic<T*>,其接口与一般的原子类型基本相同,但它提供指针算数运算。基本操作有fetch_add()和fetch_sub(),它们在存储的地址上做原子加减法并返回原值;另外还有运算符+=,-=,++,--,运算符不能提供内存顺序(memory order),它们总是使用memory_order_seq_cst。
class Foo {};
Foo some_array[5];
std::atomic<Foo*> p(some_array);
Foo* x = p.fetch_add(2);
assert(x == some_array);
assert(p.load() == &some_array[2]);
x = (p -= 1);
assert(x == &some_array[1]);
assert(p.load() == &some_array[1]);
标准整型原子类型
标准整型原子类型如std::atomic<int>或std::atomic<unsigned long long>拥有相当全面的操作可供使用:fetch_add(), fetch_sub(), fetch_and(), fetch_or(), fetch_xor(), +=,-=,&=,|=,^=,++,--,只有乘除、位移操作没有被支持。
std::atomic 模板
std::atomic 模板的存在使得用户可以创建自己的原子类型。要想创建自己的原子类型,自定义类不能有任何的虚函数或虚基类,且必须使用编译器生成的拷贝赋值运算符。其基类和非静态数据成员也需要满足该要求,这使得编译器可以使用memcpy或其它等价的赋值操作,因为没有用户写入的代码。另外,自定义类型必须是按位可比的(bitwise equality comparable),这使得可以使用memcpy和memcmp,并保证了“比较/交换”(compare/exchange)操作的正确工作。
虽然std::atomic<float>和std::atomic<double>可以使用memcpy和memcmp,但是可能由于其表达形式(科学计数法),使得原本相等的值使用memcmp得到的结果却不相同。
越复杂的数据结构就需要越多的操作,到一定复杂度时,你需要使用std::mutex。
用户定义的原子类型只能使用load()、store()、exchange()、compare_exchange_weak()、compare_exchange_strong()、以及和自定义类型实例的赋值和转换操作。
原子类型能使用的操作:
| operation | atomic_flag |
atomic<bool> |
atomic<T*> |
atomic<integral type> |
atomic<other type> |
|---|---|---|---|---|---|
test_and_set |
√ | ||||
clear |
√ | ||||
is_lock_free |
√ | √ | √ | √ | |
load |
√ | √ | √ | √ | |
store |
√ | √ | √ | √ | |
exchange |
√ | √ | √ | √ | |
compare_exchange_weak compare_exchange_strong |
√ | √ | √ | √ | |
fetch_add, += |
√ | √ | |||
fetch_sub, -= |
√ | √ | |||
fetch_or, |= |
√ | ||||
fetch_and, &= |
√ | ||||
fetch_xor, ^= |
√ | ||||
++, -- |
√ | √ |
原子类型的非成员函数
不同的原子类型也有相同的非成员函数存在:
- 大多数非成员函数相对于相应的成员函数,只是多了
atomic_前缀; - 带有
_explicit后缀的可以指定内存顺序(memory order),如std::atomic_store_explicit(&atomic_var,new_value,std::memory_order_release); - 由于成员函数拥有原子对象的隐式引用,所以非成员函数第一个参数都是原子对象的指针。
查找visual studio 2017的源代码:
// GENERAL OPERATIONS ON ATOMIC TYPES (FORWARD DECLARATIONS)
template <class _Ty>
struct atomic;
template <class _Ty>
bool atomic_is_lock_free(const volatile atomic<_Ty> *) _NOEXCEPT;
template <class _Ty>
bool atomic_is_lock_free(const atomic<_Ty> *) _NOEXCEPT;
template <class _Ty>
void atomic_init(volatile atomic<_Ty> *, _Ty) _NOEXCEPT;
template <class _Ty>
void atomic_init(atomic<_Ty> *, _Ty) _NOEXCEPT;
template <class _Ty>
void atomic_store(volatile atomic<_Ty> *, _Ty) _NOEXCEPT;
template <class _Ty>
void atomic_store(atomic<_Ty> *, _Ty) _NOEXCEPT;
template <class _Ty>
void atomic_store_explicit(volatile atomic<_Ty> *, _Ty,
memory_order) _NOEXCEPT;
template <class _Ty>
void atomic_store_explicit(atomic<_Ty> *, _Ty,
memory_order) _NOEXCEPT;
template <class _Ty>
_Ty atomic_load(const volatile atomic<_Ty> *) _NOEXCEPT;
template <class _Ty>
_Ty atomic_load(const atomic<_Ty> *) _NOEXCEPT;
template <class _Ty>
_Ty atomic_load_explicit(const volatile atomic<_Ty> *,
memory_order) _NOEXCEPT;
template <class _Ty>
_Ty atomic_load_explicit(const atomic<_Ty> *,
memory_order) _NOEXCEPT;
template <class _Ty>
_Ty atomic_exchange(volatile atomic<_Ty> *, _Ty) _NOEXCEPT;
template <class _Ty>
_Ty atomic_exchange(atomic<_Ty> *, _Ty) _NOEXCEPT;
template <class _Ty>
_Ty atomic_exchange_explicit(volatile atomic<_Ty> *, _Ty,
memory_order) _NOEXCEPT;
template <class _Ty>
_Ty atomic_exchange_explicit(atomic<_Ty> *, _Ty,
memory_order) _NOEXCEPT;
template <class _Ty>
bool atomic_compare_exchange_weak(volatile atomic<_Ty> *,
_Ty *, _Ty) _NOEXCEPT;
template <class _Ty>
bool atomic_compare_exchange_weak(atomic<_Ty> *,
_Ty *, _Ty) _NOEXCEPT;
template <class _Ty>
bool atomic_compare_exchange_weak_explicit(
volatile atomic<_Ty> *, _Ty *, _Ty,
memory_order, memory_order) _NOEXCEPT;
template <class _Ty>
bool atomic_compare_exchange_weak_explicit(
atomic<_Ty> *, _Ty *, _Ty,
memory_order, memory_order) _NOEXCEPT;
template <class _Ty>
bool atomic_compare_exchange_strong(volatile atomic<_Ty> *,
_Ty *, _Ty) _NOEXCEPT;
template <class _Ty>
bool atomic_compare_exchange_strong(atomic<_Ty> *,
_Ty *, _Ty) _NOEXCEPT;
template <class _Ty>
bool atomic_compare_exchange_strong_explicit(
volatile atomic<_Ty> *, _Ty *, _Ty,
memory_order, memory_order) _NOEXCEPT;
template <class _Ty>
bool atomic_compare_exchange_strong_explicit(
atomic<_Ty> *, _Ty *, _Ty,
memory_order, memory_order) _NOEXCEPT;
// TEMPLATED OPERATIONS ON ATOMIC TYPES (DECLARED BUT NOT DEFINED)
template <class _Ty>
_Ty atomic_fetch_add(volatile atomic<_Ty>*, _Ty) _NOEXCEPT;
template <class _Ty>
_Ty atomic_fetch_add(atomic<_Ty>*, _Ty) _NOEXCEPT;
template <class _Ty>
_Ty atomic_fetch_add_explicit(volatile atomic<_Ty>*, _Ty,
memory_order) _NOEXCEPT;
template <class _Ty>
_Ty atomic_fetch_add_explicit(atomic<_Ty>*, _Ty,
memory_order) _NOEXCEPT;
template <class _Ty>
_Ty atomic_fetch_sub(volatile atomic<_Ty>*, _Ty) _NOEXCEPT;
template <class _Ty>
_Ty atomic_fetch_sub(atomic<_Ty>*, _Ty) _NOEXCEPT;
template <class _Ty>
_Ty atomic_fetch_sub_explicit(volatile atomic<_Ty>*, _Ty,
memory_order) _NOEXCEPT;
template <class _Ty>
_Ty atomic_fetch_sub_explicit(atomic<_Ty>*, _Ty,
memory_order) _NOEXCEPT;
template <class _Ty>
_Ty atomic_fetch_and(volatile atomic<_Ty>*, _Ty) _NOEXCEPT;
template <class _Ty>
_Ty atomic_fetch_and(atomic<_Ty>*, _Ty) _NOEXCEPT;
template <class _Ty>
_Ty atomic_fetch_and_explicit(volatile atomic<_Ty>*, _Ty,
memory_order) _NOEXCEPT;
template <class _Ty>
_Ty atomic_fetch_and_explicit(atomic<_Ty>*, _Ty,
memory_order) _NOEXCEPT;
template <class _Ty>
_Ty atomic_fetch_or(volatile atomic<_Ty>*, _Ty) _NOEXCEPT;
template <class _Ty>
_Ty atomic_fetch_or(atomic<_Ty>*, _Ty) _NOEXCEPT;
template <class _Ty>
_Ty atomic_fetch_or_explicit(volatile atomic<_Ty>*, _Ty,
memory_order) _NOEXCEPT;
template <class _Ty>
_Ty atomic_fetch_or_explicit(atomic<_Ty>*, _Ty,
memory_order) _NOEXCEPT;
template <class _Ty>
_Ty atomic_fetch_xor(volatile atomic<_Ty>*, _Ty) _NOEXCEPT;
template <class _Ty>
_Ty atomic_fetch_xor(atomic<_Ty>*, _Ty) _NOEXCEPT;
template <class _Ty>
_Ty atomic_fetch_xor_explicit(volatile atomic<_Ty>*, _Ty,
memory_order) _NOEXCEPT;
template <class _Ty>
_Ty atomic_fetch_xor_explicit(atomic<_Ty>*, _Ty,
memory_order) _NOEXCEPT;
std::atomic_flag的非成员函数名与上面有些不同:
inline bool atomic_flag_test_and_set(volatile atomic_flag *_Flag) _NOEXCEPT
{ // atomically set *_Flag to true and return previous value
return (_Atomic_flag_test_and_set(&_Flag->_My_flag, memory_order_seq_cst));
}
inline bool atomic_flag_test_and_set(atomic_flag *_Flag) _NOEXCEPT
{ // atomically set *_Flag to true and return previous value
return (_Atomic_flag_test_and_set(&_Flag->_My_flag, memory_order_seq_cst));
}
inline bool atomic_flag_test_and_set_explicit(
volatile atomic_flag *_Flag, memory_order _Order) _NOEXCEPT
{ // atomically set *_Flag to true and return previous value
return (_Atomic_flag_test_and_set(&_Flag->_My_flag, _Order));
}
inline bool atomic_flag_test_and_set_explicit(
atomic_flag *_Flag, memory_order _Order) _NOEXCEPT
{ // atomically set *_Flag to true and return previous value
return (_Atomic_flag_test_and_set(&_Flag->_My_flag, _Order));
}
inline void atomic_flag_clear(volatile atomic_flag *_Flag) _NOEXCEPT
{ // atomically clear *_Flag
_Atomic_flag_clear(&_Flag->_My_flag, memory_order_seq_cst);
}
inline void atomic_flag_clear(atomic_flag *_Flag) _NOEXCEPT
{ // atomically clear *_Flag
_Atomic_flag_clear(&_Flag->_My_flag, memory_order_seq_cst);
}
inline void atomic_flag_clear_explicit(
volatile atomic_flag *_Flag, memory_order _Order) _NOEXCEPT
{ // atomically clear *_Flag
_Atomic_flag_clear(&_Flag->_My_flag, _Order);
}
inline void atomic_flag_clear_explicit(
atomic_flag *_Flag, memory_order _Order) _NOEXCEPT
{ // atomically clear *_Flag
_Atomic_flag_clear(&_Flag->_My_flag, _Order);
}
C++ 标准库也提供了以原子的方式访问std::shared_ptr<>实例的非成员函数,这打破了只有原子类型才能使用原子操作的原则,因为std::shared_ptr<>决然不是原子类型。但C++标准委员会觉得提供这些额外的函数很重要,支持的原子操作有:load、store、exchange、compare/exchange,这些操作作为标准原子类型相同操作的重载,使用std::shared_ptr<>*当做第一个参数,并且根据是否带有_explicit后缀决定是否可以指定内存顺序(memory order),还可以使用std::atomic_is_lock_free(shared_ptr<> *)确认实现是否使用了内部锁。
std::shared_ptr<my_data> p;
void update_global_data()
{
std::shared_ptr<my_data> local(new my_data);
std::atomic_store(&p, local);
}
void process_global_data()
{
std::shared_ptr<my_data> local = std::atomic_load(&p);
process_data(local);
}
同步操作与强制顺序
// 在不同的线程中读写变量
#include <vector>
#include <atomic>
#include <thread>
#include <iostream>
std::vector<int> data;
std::atomic<bool> data_ready(false);
void reader_thread()
{
while (!data_ready.load())
{
std::this_thread::sleep_for(std::chrono::milliseconds(1));
}
std::cout << "The answer = " << data[0] << "\n";
}
void writer_thread()
{
data.push_back(42);
data_ready = true;
}
忽略循环等待的低效率,上面的程序保证了数据的写入在data_ready置位之前,数据的读取在data_ready的置位之后,所以保证了数据的读取在写入之后。这看起来好像是理所当然的,但是原子操作还有其它的顺序选项。
synchronizes-with,happen-before
有两个非常重要的关系类型:同步(synchronizes-with)、发生在之前(happen-before)。
The basic idea is this: a suitably tagged atomic write operation W on a variable x synchronizes-with a suitably tagged atomic read operation on x that reads the value stored by either that write (W), or a subsequent atomic write operation on x by the same thread that performed the initial write W, or a sequence of atomic read-modify-write operations on x (such as fetch_add() or compare_exchange_weak()) by any thread, where the value read by the first thread in the sequence is the value written by W.
- synchronize-with:阅读这篇文章,如果两个操作有同步关系,就会有happen-before关系。
- happen-before:在单线程中,如果一条语句在另一条之前,那么这条语句happen-before另一条;但如果两个操作发生在同一条语句中,那么这两个操作的顺序根据编译器的不同是不确定的。多线程中,如果一个线程中的操作A比另一个线程中的操作B先发生,那么称A inter-thread happen-before B。
当一个线程中的操作A synchronize-with 另一个线程中的操作B时,那么A inter-thread happen-before B。
#include <iostream>
#include <cstdlib>
void foo(int a, int b)
{
std::cout << a << ", " << b << std::endl;
}
int get_num()
{
static int i = 0;
return ++i;
}
int main()
{
// get_num()的调用顺序是不确定的
foo(get_num(), get_num());
getchar();
return EXIT_SUCCESS;
}
原子操作内存顺序(memory order)
原子类型操作有六个可选的内存顺序(memory order)选项:memory_order_relaxed, memory_order_consume, memory_order_acquire, memory_order_release, memory_order_acq_rel, memory_order_seq_cst,所有操作的默认内存顺序(memory order)都是memory_order_seq_cst。它们被分成三个模型:
- 序列一致(sequentially consistent)顺序:
memory_order_seq_cst; - 获取释放(acquire-release)顺序:
memory_order_consume,memory_order_acquire,memory_order_release,memory_order_acq_rel; - 自由(relaxed)顺序:
memory_order_relaxed。
这些模型在不同CPU架构下的功耗是不同的,如何选择需要了解它们是怎样影响程序的行为的。
序列一致(sequentially consistent)顺序
如果所有原子类型的实例的操作都是序列一致(sequentially consistent)的,那么多线程的行为就像所有这些操作以一定的顺序在单线程中运行一样,这就是为什么它是默认内存顺序(memory order)的原因。你必须对所有线程使用序列一致(sequentially consistent),才能获得这一特点。
序列一致(sequentially consistent)是最简单、最直观的排序,但是由于其需要对所有线程进行全局同步,所以它也是最昂贵的内存排序(memory order)。在一个多处理器系统上,使用序列一致(sequentially consistent)可能会导致处理器间进行大量且耗时的通信工作。
// 一个使用序列一致(sequentially consistent)的简单例子
#include <atomic>
#include <thread>
#include <cassert>
std::atomic<bool> x, y;
std::atomic<int> z;
void write_x()
{
x.store(true, std::memory_order_seq_cst);
}
void write_y()
{
y.store(true, std::memory_order_seq_cst);
}
void read_x_then_y()
{
while (!x.load(std::memory_order_seq_cst));
if (y.load(std::memory_order_seq_cst))
++z;
}
void read_y_then_x()
{
while (!y.load(std::memory_order_seq_cst));
if (x.load(std::memory_order_seq_cst))
++z;
}
int main()
{
x = false;
y = false;
z = 0;
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
assert(z.load() != 0);
}
上面的示例中,assert永远不会造成中断,其运行情况可以分为三种:
- 如果
x.store发生在y.store之前,且read_x_then_y的y.load发生在y.store之前,那么由于read_y_then_x中x.load一定是发生在y.store之后,所以x.load一定发生在x.store之后,所以x.load一定返回true,导致z递增加一; - 上面情况的对称;
- 不管
x.store和y.store谁先发生,如果load都发生在store之后,那么z会递增两次;
非序列一致(non-sequentially consistent memory)顺序
一旦跨出序列一致(sequentially consistent)的世界,事情就开始变得复杂起来。其中最大的问题就是:再也没有一个单一的全局的事件顺序了(there’s no longer a single global order of events)。这意味着:即使是同一个操作,不同的线程也将看到不同的视界(different views),你必须将不同线程中操作的精神模型(mental model)整洁的交错在一起。
不仅你必须确保事件是真正并发的,并且线程并不需要去遵守事件的顺序(Not only do you have to account for things happening truly concurrently, but threads don’t have to agree on the order of events)。即使不同线程跑的是同一段代码,由于不同CPU缓存和内部缓冲区在同一个内存区里面可以存储不同的值,导致不同线程的操作缺少了严格的顺序限制。
在没有其他排序限制的情况下,唯一的要求是:所有线程都必须遵守每个变量的修改顺序(modification order)。不同变量的操作在不同线程中可以呈现出不同的顺序,只要所观察到的值与施加的任何排序约束一致。
自由(relaxed)顺序
使用自由(relaxed)顺序的原子操作没有同步(synchronizes-with)关系。单一线程中同一变量的操作依然遵守发生在之前(happen-before)关系,但是线程间几乎不需要相对顺序。唯一的要求是:同一线程中对同一个原子变量的访问不能被重新排序。一旦给定的线程已经看到一个原子变量的特定的值,那么该线程随后的读操作就不能获取该变量更早的值了。
在没有附加同步操作的情况下,使用memory_order_relaxed时线程间共享的唯一东西就是:每个变量的修改顺序(modification order)。
// 一个使用自由(relaxed)顺序的简单例子
#include <atomic>
#include <thread>
#include <cassert>
std::atomic<bool> x, y;
std::atomic<int> z;
void write_x_then_y()
{
x.store(true, std::memory_order_relaxed);
y.store(true, std::memory_order_relaxed);
}
void read_y_then_x()
{
while (!y.load(std::memory_order_relaxed));
if (x.load(std::memory_order_relaxed))
++z;
}
int main()
{
x = false;
y = false;
z = 0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load() != 0);
}
上面的示例中,assert可能发生中断:根据自由(relaxed)顺序只支持同一变量在同一线程中的发生在之前(happen-before)关系,得出x、y的store之间是没有发生的先后关系的;根据自由(relaxed)顺序并不支持同步(synchronizes-with)关系,得出x、y的store和load之间也没有先后关系;最后根据以上两点,得出:x.load可能发生在x.store之前,所以z可能为0。
// 一个使用自由(relaxed)顺序的复杂例子
#include <thread>
#include <atomic>
#include <iostream>
std::atomic<int> x(0), y(0), z(0);
std::atomic<bool> go(false);
unsigned const loop_count = 10;
struct read_values
{
int x, y, z;
};
read_values values1[loop_count];
read_values values2[loop_count];
read_values values3[loop_count];
read_values values4[loop_count];
read_values values5[loop_count];
void increment(std::atomic<int>* var_to_inc, read_values* values)
{
while (!go)
std::this_thread::yield();
for (unsigned i = 0; i<loop_count; ++i)
{
values[i].x = x.load(std::memory_order_relaxed);
values[i].y = y.load(std::memory_order_relaxed);
values[i].z = z.load(std::memory_order_relaxed);
var_to_inc->store(i + 1, std::memory_order_relaxed);
std::this_thread::yield();
}
}
void read_vals(read_values* values)
{
while (!go)
std::this_thread::yield();
for (unsigned i = 0; i<loop_count; ++i)
{
values[i].x = x.load(std::memory_order_relaxed);
values[i].y = y.load(std::memory_order_relaxed);
values[i].z = z.load(std::memory_order_relaxed);
std::this_thread::yield();
}
}
void print(read_values* v)
{
for (unsigned i = 0; i<loop_count; ++i)
{
if (i)
std::cout << ",";
std::cout << "(" << v[i].x << "," << v[i].y << "," << v[i].z << ")";
}
std::cout << std::endl;
}
int main()
{
std::thread t1(increment, &x, values1);
std::thread t2(increment, &y, values2);
std::thread t3(increment, &z, values3);
std::thread t4(read_vals, values4);
std::thread t5(read_vals, values5);
go = true; // 确保线程几乎同时开始循环
t5.join();
t4.join();
t3.join();
t2.join();
t1.join();
print(values1);
print(values2);
print(values3);
print(values4);
print(values5);
}
上面代码运行起来稍微有些复杂,
- 首先还是从主函数开始看:主函数开了五个线程,其中三个线程除了读取全局原子变量之外,还对传入的原子参数进行了更新操作,然后是两个对原子变量只读线程,在所有线程完成之后,对所有赋值后的结构体数组变量进行打印操作;
- 再来看三个进行过原子更新操作的线程:根据自由(relaxed)顺序支持同一变量在同一线程中的发生在之前(happen-before)关系,所以线程t1对x的操作是有先后关系的,即load->store->load->…->store,t2、t3类似,所以values1所有元素的x成员、values2所有元素的y成员、values3所有元素的z成员一定是0123456789;
- 最后根据自由(relaxed)顺序并不支持同步(synchronizes-with)关系,所以所有线程对各个原子变量操作的相对顺序并没有保证,所以其它值将是0~10之间的任意值,但是因为单一原子变量的load是有先后关系的,所以values同一位置的值将会呈现不严格递增(大于等于)趋势。
一种visual studio 2017的结果是:
(0,4,4),(1,7,7),(2,10,10),(3,10,10),(4,10,10),(5,10,10),(6,10,10),(7,10,10),(8,10,10),(9,10,10)
(0,0,0),(0,1,1),(0,2,2),(0,3,3),(0,4,4),(1,5,5),(1,6,6),(1,7,7),(2,8,8),(2,9,9)
(0,0,0),(0,1,1),(0,2,2),(0,3,3),(0,4,4),(1,5,5),(1,6,6),(1,7,7),(2,8,8),(2,9,9)
(10,10,10),(10,10,10),(10,10,10),(10,10,10),(10,10,10),(10,10,10),(10,10,10),(10,10,10),(10,10,10),(10,10,10)
(0,3,3),(1,6,6),(2,8,8),(3,10,10),(4,10,10),(5,10,10),(6,10,10),(7,10,10),(8,10,10),(9,10,10)
再次运行:
(0,4,4),(1,7,7),(2,9,10),(3,10,10),(4,10,10),(5,10,10),(6,10,10),(7,10,10),(8,10,10),(9,10,10)
(0,0,0),(0,1,1),(0,2,2),(0,3,3),(0,4,4),(1,5,5),(1,6,6),(1,7,7),(2,8,8),(2,9,9)
(0,0,0),(0,1,1),(0,2,2),(0,3,3),(0,4,4),(1,5,5),(1,6,6),(1,7,7),(2,8,8),(2,9,9)
(0,0,0),(0,1,1),(0,2,2),(0,2,3),(0,3,3),(0,4,4),(1,5,5),(1,6,6),(1,7,7),(2,8,8)
(0,3,3),(1,6,6),(2,8,8),(3,10,10),(4,10,10),(5,10,10),(6,10,10),(7,10,10),(8,10,10),(9,10,10)
自由原子操作非常难处理,除非特别必要,否则不要使用自由(relaxed)顺序。
获取-释放(acquire-release)顺序
获取-释放(acquire-release)顺序是自由(relaxed)顺序的加强版,所有操作仍然没有统一的排序,但是它加入了一些同步。在这种顺序模型下,原子加载(load)是获取(acquire)操作(memory_order_acquire),原子存储(store)是释放(release)操作(memory_order_release),原子读改写(read-modify-write)是获取(acquire)、释放(release)、或者两者都有的操作(memory_order_acq_rel)。
同步是成对的,一个线程获取(acquire),一个线程释放(release)。同一原子变量的释放(release)操作与获取(acquire)操作是同步的,这意味着同一原子变量的释放操作与获取操作是有先后顺序的,不同线程仍然可以看到不同的顺序,但这些顺序是有限制的。
// 一个使用获取-释放(acquire-release)顺序的简单例子
#include <atomic>
#include <thread>
#include <cassert>
std::atomic<bool> x, y;
std::atomic<int> z;
void write_x()
{
x.store(true, std::memory_order_release);
}
void write_y()
{
y.store(true, std::memory_order_release);
}
void read_x_then_y()
{
while (!x.load(std::memory_order_acquire));
if (y.load(std::memory_order_acquire))
++z;
}
void read_y_then_x()
{
while (!y.load(std::memory_order_acquire));
if (x.load(std::memory_order_acquire))
++z;
}
int main()
{
x = false;
y = false;
z = 0;
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
assert(z.load() != 0);
}
上面的示例中,assert可能发生中断。主函数开了四个线程,其中两个写,两个读;线程read_x_then_y保证x.load一定发生在x.store之后,但y.load是不是发生在y.store之后并没有保证;同理,线程read_y_then_x中x.load也没有保证发生在x.store之后;如果read_x_then_y看到的顺序是x.store在y.store之前,read_y_then_x看到的顺序是y.store在x.store之前,那么z不会发生改变。
// 一个体现获取-释放(acquire-release)顺序优点的简单例子
#include <atomic>
#include <thread>
#include <cassert>
std::atomic<bool> x, y;
std::atomic<int> z;
void write_x_then_y()
{
x.store(true, std::memory_order_relaxed);
y.store(true, std::memory_order_release);
}
void read_y_then_x()
{
while (!y.load(std::memory_order_acquire));
if (x.load(std::memory_order_relaxed))
++z;
}
int main()
{
x = false;
y = false;
z = 0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load() != 0);
}
上面的示例中,assert永远不会发生中断。read_y_then_x保证y.load一定发生在y.store之前,memory_order_acquire保证在memory_order_release之前的所有修改(原子的、非原子的)都能被其看见,所以x.load一定发生在x.store之后,所以z一定会递增。但如果y.load不是在循环里,结果就会不同。
// memory_order_acquire保证在memory_order_release之前的所有修改都能被其看见
#include <atomic>
#include <thread>
#include <cassert>
std::atomic<int> data[5];
std::atomic<bool> sync1(false), sync2(false);
void thread_1()
{
data[0].store(42, std::memory_order_relaxed);
data[1].store(97, std::memory_order_relaxed);
data[2].store(17, std::memory_order_relaxed);
data[3].store(-141, std::memory_order_relaxed);
data[4].store(2003, std::memory_order_relaxed);
sync1.store(true, std::memory_order_release);
}
void thread_2()
{
while (!sync1.load(std::memory_order_acquire));
sync2.store(true, std::memory_order_release);
}
void thread_3()
{
while (!sync2.load(std::memory_order_acquire));
assert(data[0].load(std::memory_order_relaxed) == 42);
assert(data[1].load(std::memory_order_relaxed) == 97);
assert(data[2].load(std::memory_order_relaxed) == 17);
assert(data[3].load(std::memory_order_relaxed) == -141);
assert(data[4].load(std::memory_order_relaxed) == 2003);
}
int main()
{
std::thread t1(thread_1);
std::thread t2(thread_2);
std::thread t3(thread_3);
t1.join();
t2.join();
t3.join();
}
上面的示例中,thread_2作为中间线程,使得thread_1与thread_3进行了同步。为了验证memory_order_release之后的修改是否能被memory_order_acquire看见,修改上面程序,添加一个额外的int全局变量test,在memory_order_release之后改变它的值,为了确保验证的正确性,添加一个一秒的延时:
// memory_order_release之后的修改并不一定能被memory_order_acquire看见
#include <atomic>
#include <thread>
#include <cassert>
std::atomic<int> data[5];
std::atomic<bool> sync1(false), sync2(false);
int test{ 0 };
void thread_1()
{
data[0].store(42, std::memory_order_relaxed);
data[1].store(97, std::memory_order_relaxed);
data[2].store(17, std::memory_order_relaxed);
data[3].store(-141, std::memory_order_relaxed);
data[4].store(2003, std::memory_order_relaxed);
sync1.store(true, std::memory_order_release);
std::this_thread::sleep_for(std::chrono::milliseconds(1000));
test = 233;
}
void thread_2()
{
while (!sync1.load(std::memory_order_acquire));
sync2.store(true, std::memory_order_release);
}
void thread_3()
{
while (!sync2.load(std::memory_order_acquire));
assert(data[0].load(std::memory_order_relaxed) == 42);
assert(data[1].load(std::memory_order_relaxed) == 97);
assert(data[2].load(std::memory_order_relaxed) == 17);
assert(data[3].load(std::memory_order_relaxed) == -141);
assert(data[4].load(std::memory_order_relaxed) == 2003);
assert(test == 233); // fire
}
int main()
{
std::thread t1(thread_1);
std::thread t2(thread_2);
std::thread t3(thread_3);
t1.join();
t2.join();
t3.join();
}
你也可以使用读改写(read-modify-write)操作来实现上上个示例:
std::atomic<int> sync(0);
void thread_1()
{
// ...
sync.store(1, std::memory_order_release);
}
void thread_2()
{
int expected = 1;
while (!sync.compare_exchange_strong(expected, 2,
std::memory_order_acq_rel))
expected = 1;
}
void thread_3()
{
while (sync.load(std::memory_order_acquire)<2);
// ...
}
如果你确认不需要严格的序列一致(sequentially consistent)顺序,使用获取-释放(require-release)顺序是个不错的选择。
memory_order_consume
memory_order_consume是获取-释放(require-release)顺序模型的一部分。它很特别:它完全依赖于数据。
这里有两种新的数据依赖关系:
- 携带依赖(carries-a-dependency-to):如果操作A的结果被用作操作B的操作数,则A carries-a-dependency-to B。该关系具有传递性。
- 前序依赖(dependency-ordered-before):该关系以标记为
memory_order_consume的原子加载(load)操作进行引入,它是memory_order_acquire的一个特例;一个标记为memory_order_release、memory_order_acq_rel或memory_order_seq_cst的存储(store)操作A前序依赖于一个标记为memory_order_consume的加载(load)操作B,如果B读取的是A存储(store)的值的话。如果A dependency-ordered-before B,那么A inter-thread happen-before B。
// 一个使用memory_order_consume的简单例子
#include <atomic>
#include <thread>
#include <cassert>
struct X
{
int i;
std::string s;
};
std::atomic<X*> p;
std::atomic<int> a;
void create_x()
{
X* x = new X;
x->i = 42;
x->s = "hello";
a.store(99, std::memory_order_relaxed);
p.store(x, std::memory_order_release);
}
void use_x()
{
X* x;
while (!(x = p.load(std::memory_order_consume)))
std::this_thread::yield();
assert(x->i == 42);
assert(x->s == "hello");
assert(a.load(std::memory_order_relaxed) == 99);
}
int main()
{
std::thread t1(create_x);
std::thread t2(use_x);
t1.join();
t2.join();
}
上面的示例中,x的值 dependency-ordered-before p,所以x的值一定是p.store存储的值,所以关于x的断言(assert)永远不会发生中断;但是a的断言(assert)并不依赖于p的值,所以它可能发生中断。
当一个值并不 carries-a-dependency-to memory_order_consume加载(load)的值时,使用std::kill_dependency可以让编译器有更大的空间进行优化,搞不清楚就去SOF看看,但是我觉得并没有必要使用这个东西:
int global_data[] = { ... };
std::atomic<int> index;
void f()
{
int i = index.load(std::memory_order_consume);
do_something_with(global_data[std::kill_dependency(i)]);
}
release sequences and synchronize-with
如果store以memory_order_release、memory_order_acq_rel或memory_order_seq_cst标记,load以memory_order_consume、memory_order_acquire或memory_order_seq_cst标记,且链上的每一load操作得到的值都是前一store操作写下的值,那么这个操作链组成了一个释放序列(release sequences),并且初始化store synchronize-with (对应memory_order_acquire和memory_order_seq_cst)或 dependency-ordered-before (对应memory_order_consume)最终load。该链上任何原子读改写(read-modify-write)操作可以拥有任何内存顺序(memory order),甚至memory_order_relaxed。
// 使用原子操作从一个队列中读值
#include <atomic>
#include <thread>
#include <vector>
#include <iostream>
std::vector<int> queue_data;
std::atomic<int> count;
void populate_queue()
{
unsigned const number_of_items = 20;
queue_data.clear();
for (unsigned i = 0; i<number_of_items; ++i)
{
queue_data.push_back(i);
}
count.store(number_of_items, std::memory_order_release);
}
void process(int &i) { ++i; }
void consume_queue_items()
{
while (true)
{
int item_index;
// fetch_sub: 调用值减去参数值,并返回原值
if ((item_index = count.fetch_sub(1, std::memory_order_acquire)) <= 0)
{
std::this_thread::yield();
continue;
}
process(queue_data[item_index - 1]);
}
}
int main()
{
std::thread a(populate_queue);
std::thread b(consume_queue_items);
std::thread c(consume_queue_items);
a.join();
b.detach();
c.detach();
for (auto &i : queue_data)
{
std::cout << i << " ";
}
std::cout << std::endl;
}
结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
分析:我们知道当consumer只开一个时,由于memory_order_acquire会看到memory_order_release之前的全部修改,所以代码会工作的很好。但是现在consumer开了两个,那么第二个consumer就可能看到第一个consumer修改后的值,除非第一个fetch_sub使用memory_order_release,但这会带来不必要的同步;如果没有释放序列(release sequence)规则或者fetch_sub没有使用memory_order_release的话,没有什么能够要求第二个consumer能够看到queue_data的store操作。庆幸的是,fetch_sub参与了释放序列(release sequence),所以store也同步到第二个fetch_sub,并且两个consumer也没有进行同步。下面图的实线显示了发生在之前(happens-before)关系,虚线显示了释放序列(release sequence)。
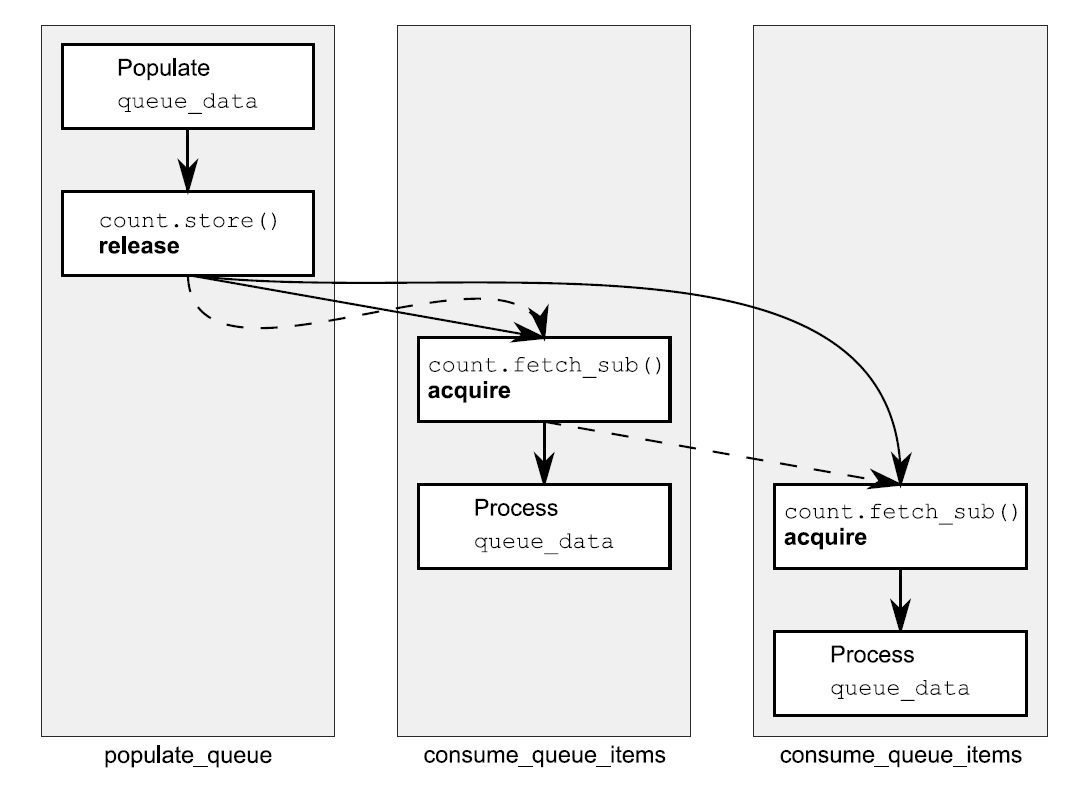
这里的链可以有任意数量的连接,只要它们都是读改写(read-modify-write)操作,那么store将会同步到每一个标记为memory_order_acquire的操作。
fences
fences是在没有修改数据的情况下强制内存顺序(memory order)限制的操作,典型的是与memory_order_relaxed的原子操作一起使用。fences是全局操作,并且会影响线程中执行了fences的原子操作的顺序。fences通常也被称为内存屏障(memory barriers),因为它们就像在代码中画出了一条某些(certain)操作无法跨越的线一样。
你应该知道,不同变量上的relaxed操作根据编译器或硬件的不同,可以被任意排序,但fences限制了这个自由,并且引入了happen-before和synchronize-with关系。
// 一个使用atomic_thread_fence的简单例子
#include <atomic>
#include <thread>
#include <cassert>
std::atomic<bool> x, y;
std::atomic<int> z;
void write_x_then_y()
{
x.store(true, std::memory_order_relaxed);
std::atomic_thread_fence(std::memory_order_release);
y.store(true, std::memory_order_relaxed);
}
void read_y_then_x()
{
while (!y.load(std::memory_order_relaxed));
std::atomic_thread_fence(std::memory_order_acquire);
if (x.load(std::memory_order_relaxed))
++z;
}
int main()
{
x = false;
y = false;
z = 0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load() != 0);
}
上面的assert永远不会发生中断,因为atomic_thread_fence使得x.store一定发生在x.load之前,所以z一定会递增;但是如果没有atomic_thread_fence的话,assert可能会发生中断,因为x.store与y.store没有绝对的相对顺序。
This is the general idea with fences: if an acquire operation sees the result of a store that takes place after a release fence, the fence synchronizes-with that acquire operation; and if a load that takes place before an acquire fence sees the result of a release operation, the release operation synchronizes-with the acquire fence.
无锁数据结构示例
无锁数据结构依赖于原子操作,及其关联的memory order,用以确保数据以正确的顺序被其他线程看到。刚开始我们会使用默认的memory order–memory_order_seq_cst,然后会用memory_order_acquire、memory_order_release、甚至memory_order_relaxed来减少一些顺序的限制。虽然这些示例都没有直接使用mutex,但是只有std::atomic_flag保证其实现不会使用mutex。在一些环境中,无锁数据结构可能实际上使用的是内部锁实现的,在这种情况下,使用有锁数据结构可能会更加适合,总之:在选择实现方式时,你需要确认自己的需求,并配置复合这些要求的各种选项。
Writing a thread-safe stack without locks
stack的基本前提是相对简单的:last in, first out(LIFO)。所以有一件事是非常重要的:一旦一个值被添加到stack,那么它可以马上被其他线程安全的获取,且只能有一个线程获取到。
最简单的stack使用linked list实现的:head指针指向第一个节点,然后head->next指向下一个节点。添加一个节点在单线程中需要做以下操作:
- 创建一个新节点;
- 设置该新节点的next到当前head;
- 更新head,使其指向该新节点。
该操作在单线程中是没有问题的,但是如果有两个线程同时在添加节点,那么步骤2和步骤3之间就可能有条件竞争,在当前线程做完步骤2后,开始步骤3前,也许其它线程已经修改了head指向,那么其他线程添加的节点就失去了指向(稍微画个图就明白了),就像被丢弃了一样,但是可能因为没有被释放,会一直占用着内存。解决方案就是:在步骤3中使用原子compare/exchange操作,用以确保步骤2读取到的head没有被修改,如果其被修改了,那么重新开始。
template<typename T>
class lock_free_stack
{
private:
struct node
{
T data;
node* next;
node(T const& data_) :
data(data_)
{}
};
std::atomic<node*> head;
public:
void push(T const& data)
{
node* const new_node = new node(data);
new_node->next = head.load();
// 若new_node->next与head.load()相等,则head被赋值为new_node,循环结束
// 否则,new_node->next被赋值为head.load(),再次循环
// 使用weak而非strong是因为前者在某些架构上能使代码更加优化
while (!head.compare_exchange_weak(new_node->next, new_node));
}
};
上面唯一可能发生异常的地方是new node,但是这并不影响这个数据结构,因为它并没有修改任何节点;由于没有lock,也不会有deadlock的危险;条件竞争(race condition)也用compare/exchange解决了。所以现在我们有了一个安全的无锁的向stack添加数据的接口了,接下来我们需要设计一个pop接口。在单线程中,pop的步骤如下:
- 读取当前head;
- 读取
head->next; - 更新head,使其指向
head->next; - 返回获取到的节点的数据;
- 删除获取的节点。
还是老问题,如果有两个线程同时pop,那么这两个线程在步骤1可能读取到相同的head,如果其中一个线程A在另一个线程B执行步骤2前就完成了所有步骤,那么此时B读取到的head就是被删除的指针,继续使用将会造成未定义行为,所以我们先不删除节点。另一个问题是:A和B读取到的是相同的head,那么它们会返回相同的节点数据,这是违反stack的意图的。你可以用在push中相同的方法来解决这个问题,那就是使用compare/exchange操作:使用compare/exchange来更新head,如果失败了,要么是有一个新的节点被push了,要么就是另一个线程pop了你想pop的节点,不管哪个原因,你需要返回step1重新开始;如果成功了那么你就是唯一一个执行pop操作的线程,你可以安全的执行step4。
void pop(T& result)
{
node* old_head = head.load();
while (!head.compare_exchange_weak(old_head, old_head->next));
result = old_head->data;
}
上面的代码虽然看起来简洁又nice,但是还是有节点泄露的问题:
- 首先,当列表为空时,pop是不能工作的,因为此时
head.load()是nullptr,使用其next会造成未定义行为,你可以在一个while中循环检测nullptr,或者抛出一个empty stack异常,或者返回一个bool值用以指示成功或失败; - 第二个问题是异常安全问题,在基础篇我们讲过,直接返回值如果发生异常的话,那么原值就会丢失,在这种情况下,传入引用是一个可选的方法,你可以确保在异常发生时,stack的值保持不变,然而不幸的是,你不能这么做,你只能在你知道自己是唯一一个返回该节点的情况下才能安全的复制数据,这意味着该节点已经被stack移除了,因此传入引用没有任何优势,直接返回也是可以的。如果你想安全的返回值,你可以选择返回一个智能指针,nullptr用来指明没有值可以返回,但是数据也需要内存分配,这也可能发生异常,你可以将内存分配放到push中去。
template<typename T>
class lock_free_stack
{
private:
struct node
{
std::shared_ptr<T> data;
node* next;
node(T const& data_) :
data(std::make_shared<T>(data_))
{}
};
std::atomic<node*> head;
public:
void push(T const& data)
{
node* const new_node = new node(data);
new_node->next = head.load();
while (!head.compare_exchange_weak(new_node->next, new_node));
}
std::shared_ptr<T> pop()
{
node* old_head = head.load();
while (old_head &&
!head.compare_exchange_weak(old_head, old_head->next));
return old_head ? old_head->data : std::shared_ptr<T>();
}
};
上面的代码将data数据类型修改为了std::shared_ptr,pop中也检查了head为空的情况。整个数据结构时无锁但却不是无等待的,因为两个while可能一直在循环。
Stopping those pesky leaks: managing memory in lock-free data structures
众所周知,C++是没有像java或C#那样的垃圾回收机制的,所以你需要自己清理pop中的old_head。但是在确定没有其他线程在使用该指针前,你是不能做delete操作的。push一旦将节点添加到stack之后,就不再与该节点有任何关系了,所以pop肯定是唯一一个可以接触节点并安全删除节点的线程。
另一方面,如果你需要处理多个线程对同一个stack调用pop的情况,那么你需要一些方法来跟踪什么时候删除节点是安全的。这实际上意味着你需要为节点写一个专用的垃圾回收器,这听起来可能有些恐怖,实际上也相当棘手,但并不是那么糟糕:你仅仅只需要检查pop访问的节点,push中的节点你并不需要担心,因为直到节点被添加到stack,push中的节点只有它一个线程能访问。
如果没有线程在调用pop,删除所有待删除的节点是绝对安全的。因此,当你提取完数据之后,你可以将节点添加到“待删除”列表,然后等待没有线程在调用pop时将它们全部删除。很显然,你如何才能知道没有线程在调用pop呢,很简单,在pop里添加一个计数器即可:进入时递增计数器,退出时递减计数器。当然该计数器也必须是原子的,使用整型原子变量就可以担此大任。
template<typename T>
class lock_free_stack
{
private:
struct node
{
std::shared_ptr<T> data;
node* next;
node(T const& data_) :
data(std::make_shared<T>(data_))
{}
};
std::atomic<node*> head;
std::atomic<unsigned> threads_in_pop;
std::atomic<node*> to_be_deleted;
static void delete_nodes(node* nodes)
{
while (nodes)
{
node* next = nodes->next;
delete nodes;
nodes = next;
}
}
void try_reclaim(node* old_head)
{
// 当前只有你一个线程在调用pop,可以安全的删除old_head和待删除的节点
if (threads_in_pop == 1)
{
// exchange: 交换存储的值与传入的值,返回交换后传入的值
node* nodes_to_delete = to_be_deleted.exchange(nullptr);
// 如果threads_in_pop递减之后为0,那么意味着没有其它线程可以访问待删除节点列表
if (!--threads_in_pop)
{
delete_nodes(nodes_to_delete);
}
// 如果threads_in_pop递减之后不为0,那么需要将交换出来的节点重新放回到待删除列表
else if (nodes_to_delete)
{
chain_pending_nodes(nodes_to_delete);
}
delete old_head;
}
// 若当前不止你一个线程在调用pop,那么将old_head添加到待删除列表
else
{
chain_pending_node(old_head);
--threads_in_pop;
}
}
void chain_pending_nodes(node* nodes)
{
node* last = nodes;
while (node* const next = last->next)
{
last = next;
}
chain_pending_nodes(nodes, last);
}
void chain_pending_nodes(node* first, node* last)
{
last->next = to_be_deleted;
while (!to_be_deleted.compare_exchange_weak(
last->next, first));
}
void chain_pending_node(node* n)
{
chain_pending_nodes(n, n);
}
public:
void push(T const& data)
{
node* const new_node = new node(data);
new_node->next = head.load();
while (!head.compare_exchange_weak(new_node->next, new_node));
}
std::shared_ptr<T> pop()
{
++threads_in_pop;
node* old_head = head.load();
while (old_head &&
!head.compare_exchange_weak(old_head, old_head->next));
std::shared_ptr<T> res;
if (old_head)
{
// 使用swap会将传入参数的所有权移交到调用者,现在old_head可以随意删除了
res.swap(old_head->data);
}
try_reclaim(old_head); // threads_in_pop在这里递减
return res;
}
};
无锁数据结构太难了,上面是最简单的数据结构,还没设计完!其实后面还有一些分析,你可以自行查看《C++ Concurrency in Action》7.2.2节及其后面的内容。我自认为如果让我自己构建的话,我是绝对想不到这么多的,在工作中需要经常调试又很难找出错误的代码是不允许出现的,我还是比较适合带锁的数据结构,当然这只是安慰自己的借口而已,后面会跳过无锁数据结构的设计,开始并发代码设计、管理和调试的学习!