本篇内容从如何设计多线程数据结构开始,提供了一些设计规范,并实际操控了一些常用的数据结构(stack,queue,hash map,linked list),它们的设计从简单到复杂,仿照它们从设计到完成的过程,你应该能够自行设计自己的并发数据结构,预测到可能发生的条件竞争并避免,并修改至最大可能的并发性能。
本文结构
基于锁的并发数据结构设计概述
数据结构的选择是编程问题的重要组成部分,并发编程也不例外。如果一个数据结构被多个线程访问,这个数据结构要么是不可变的,要么需要设计程序用以确保改变在线程间是正确同步的。
并发设计的一条路是使用mutex,另一条路就是设计数据结构自身,用以支持并发访问,这样的数据结构被称为线程安全(thread safe)。
使用mutex序列化了线程对数据的访问,要想获得真正的并发访问,你必须对数据结构的设计仔细斟酌。保护区域越少,被序列化的操作就越少,并发访问的潜力就越大。
在设计数据结构时,你有两方面需要思考:
- 确保访问是安全(safe)的:一个线程在修改数据时,不能被另一个线程看到中间状态;一个完整的操作不要分成几个操作写在不同的函数里;数据结构的异常处理;死锁(dead-lock)问题;等等;
- 启动真正的并发:当前锁范围内的操作是否能移到锁范围外执行?该数据结构的不同部分能否使用不同的mutex来保护?是不是所有操作都需要相同层级的保护?有没有不改变操作语义又能提升并发概率的简单操作?等等。
基于锁的简单并发数据结构设计
基于锁的并发数据结构设计就是:确保在访问数据的时候lock了正确的mutex,并且lock的时长最短。
你需要保证数据不能在保护区域外被访问,且接口(interface)间不能有条件竞争,如果有多个锁的话还要避免死锁的发生。
stack
#pragma once
// 一个线程安全的简单stack模板
#include <exception>
#include <stack>
#include <mutex>
struct empty_stack : std::exception
{
const char* what() const throw()
{
return "empty stack.\n";
}
};
template<typename T>
class threadsafe_stack
{
private:
std::stack<T> data;
mutable std::mutex m;
public:
threadsafe_stack() {}
threadsafe_stack(const threadsafe_stack& other)
{
std::lock_guard<std::mutex> lock(other.m);
data = other.data;
}
threadsafe_stack& operator=(const threadsafe_stack&) = delete;
void push(T new_value)
{
std::lock_guard<std::mutex> lock(m);
data.push(std::move(new_value));
}
std::shared_ptr<T> pop()
{
std::lock_guard<std::mutex> lock(m);
if (data.empty()) throw empty_stack();
std::shared_ptr<T> const res(
std::make_shared<T>(std::move(data.top())));
data.pop();
return res;
}
void pop(T& value)
{
std::lock_guard<std::mutex> lock(m);
if (data.empty()) throw empty_stack();
value = std::move(data.top());
data.pop();
}
bool empty() const
{
std::lock_guard<std::mutex> lock(m);
return data.empty();
}
};
#include <iostream>
#include <cstdlib>
#include <thread>
#include "myStack.h"
threadsafe_stack<int> g_stack;
void add_data()
{
int loop_count = 10;
for (int i = 0; i < loop_count; ++i)
{
g_stack.push(i);
}
}
void print_data()
{
while (g_stack.empty())
{
std::this_thread::yield();
}
while (1)
{
try {
std::cout << *g_stack.pop() << std::endl;
}
catch(empty_stack &e){
std::cout << e.what();
break;
}
}
}
int main()
{
auto t1 = std::thread(add_data);
auto t2 = std::thread(print_data);
t1.join();
t2.join();
}
测试结果:
9
8
7
6
5
4
3
2
1
0
empty stack.
现在来分析上面的threadsafe_stack模板:
- 首先,每个成员函数在操作数据时,都对成员mutex进行了lock,这确保了一个时间只能有一个成员函数访问数据;
- 再来,将标准stack的top与pop放在一起是为了防止条件竞争(race condition),具体原因可参考基础篇;
- 然后,对一个mutex进行lock时可能抛出一个异常,但这非常罕见,因为这是mutex出错或者系统资源缺失造成的,但是由于该操作是第一个操作,所以就算发生异常,数据也不会被更改,所以是安全的;对一个mutex进行unlock时永远不会失败;
- 接着,对
data.push(std::move(new_value))的调用可能会抛出异常,如果value的拷贝或移动函数(当T没有移动构造函数时,std::move会调用拷贝构造函数)抛出异常,或者内存不足的话。不管哪种情况,标准stack保证是安全的; - 继续,两个pop成员函数中的
std::make_shared和std::move都可能抛出异常,但是就算抛出异常,也没有对数据进行更改,所以是安全的; - 最后,也许你觉得对代码已经分析完了,然而并不是,这里还用三个潜在的使用上的问题:
- 如果你的模板参数T是自定义类型,并且自定义了赋值运算符=,那么在使用复制构造函数或pop成员函数时,就可能造成嵌套锁,继而造成死锁(dead-lock),但是由于上锁的顺序是一定的,所以不太可能发生这个问题;
- 有两个不安全的成员函数:构造函数和析构函数。因为它们只能被调用一次。你不能在构造完成之前或析构结束之后访问其实例;
- 由于锁的原因,实际上一个时间点只有一个线程在使用这个stack工作;如果一个线程需要等待,那么它需要周期性的调用empty或pop抓取
empty_stack异常,这消耗了不必要的资源用于检测数据,或者你必须写一些额外的等待代码(如condition variables),但这又造成了不必要的中间锁,非常浪费。
queue
#pragma once
// 一个线程安全的简单queue模板
#include <queue>
#include <mutex>
template<typename T>
class threadsafe_queue
{
private:
mutable std::mutex mut;
std::queue<T> data_queue;
std::condition_variable data_cond;
public:
threadsafe_queue()
{}
void push(T new_value)
{
std::lock_guard<std::mutex> lk(mut);
data_queue.push(std::move(new_value));
data_cond.notify_one();
}
void wait_and_pop(T& value)
{
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk, [this] {return !data_queue.empty(); });
value = std::move(data_queue.front());
data_queue.pop();
}
std::shared_ptr<T> wait_and_pop()
{
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk, [this] {return !data_queue.empty(); });
std::shared_ptr<T> res(
std::make_shared<T>(std::move(data_queue.front())));
data_queue.pop();
return res;
}
bool try_pop(T& value)
{
std::lock_guard<std::mutex> lk(mut);
if (data_queue.empty())
return false;
value = std::move(data_queue.front());
data_queue.pop();
return true;
}
std::shared_ptr<T> try_pop()
{
std::lock_guard<std::mutex> lk(mut);
if (data_queue.empty())
return std::shared_ptr<T>();
std::shared_ptr<T> res(
std::make_shared<T>(std::move(data_queue.front())));
data_queue.pop();
return res;
}
bool empty() const
{
std::lock_guard<std::mutex> lk(mut);
return data_queue.empty();
}
};
#include <iostream>
#include <cstdlib>
#include <thread>
#include "myQueue.h"
threadsafe_queue<int> g_queue;
void add_data()
{
int loop_count = 10;
for (int i = 0; i < loop_count; ++i)
{
g_queue.push(i);
}
}
void print_data()
{
while (1)
{
std::cout << *g_queue.wait_and_pop() << std::endl;
}
}
int main()
{
auto t1 = std::thread(add_data);
auto t2 = std::thread(print_data);
t1.join();
t2.join();
}
测试结果(由于print_data线程永远不会自动结束,所以需要手动强制结束,应用篇里会学到线程中断的知识来解决这个问题):
0
1
2
3
4
5
6
7
8
9
^C
现在来分析上面的threadsafe_queue模板:
- 该模板与上面的stack模板类似,唯一不同的就是使用了
std::condition_variable,所以你再也不用周期性的调用empty来做等待操作了,也不用抓取empty_stack异常了; - 当有多个线程在等待时,由于调用的是
notify_one(),所以只会有一个线程被唤醒,然而当该线程发生异常时(如std::make_shared),其它线程就不会被唤醒了,这里有三个方案来解决这个问题:- 直接使用
notify_all(); - 当异常发生时,调用
notify_one()尝试唤醒其它线程; - 将
std::shared_ptr<>的初始化移到push成员函数中去,并且标准queue改为存储std::shared_ptr<>而不是直接存储数据。下面的代码展示了第三个方案:
- 直接使用
#pragma once
// 一个改善了的线程安全的简单queue模板
#include <queue>
#include <mutex>
template<typename T>
class threadsafe_queue
{
private:
mutable std::mutex mut;
std::queue<std::shared_ptr<T> > data_queue;
std::condition_variable data_cond;
public:
threadsafe_queue()
{}
void push(T new_value)
{
// 内存分配往往是非常耗时的,
// 将其放置在lock之外,极大地缩短了持有mutex的时长
std::shared_ptr<T> data(
std::make_shared<T>(std::move(new_value)));
std::lock_guard<std::mutex> lk(mut);
data_queue.push(data);
data_cond.notify_one();
}
void wait_and_pop(T& value)
{
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk, [this] {return !data_queue.empty(); });
value = std::move(*data_queue.front());
data_queue.pop();
}
bool try_pop(T& value)
{
std::lock_guard<std::mutex> lk(mut);
if (data_queue.empty())
return false;
value = std::move(*data_queue.front());
data_queue.pop();
return true;
}
std::shared_ptr<T> wait_and_pop()
{
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk, [this] {return !data_queue.empty(); });
std::shared_ptr<T> res = data_queue.front();
data_queue.pop();
return res;
}
std::shared_ptr<T> try_pop()
{
std::lock_guard<std::mutex> lk(mut);
if (data_queue.empty())
return std::shared_ptr<T>();
std::shared_ptr<T> res = data_queue.front();
data_queue.pop();
return res;
}
bool empty() const
{
std::lock_guard<std::mutex> lk(mut);
return data_queue.empty();
}
};
A thread-safe queue using fine-grained locks and condition variables
上面的stack和queue只有一个需要保护的成员,因此只需要一个mutex。为了使用细粒度的锁,你需要观察queue的内部组成,并且关联一个mutex到每一个数据项。
最简单的队列数据结构就是单链表了。
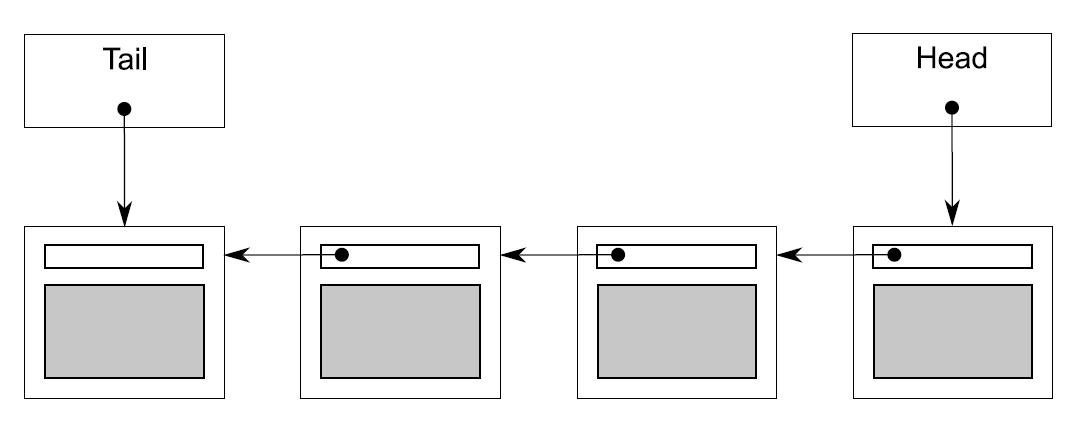
#pragma once
// 一个简单的单线程队列实现
template<typename T>
class queue
{
private:
struct node
{
T data;
std::unique_ptr<node> next;
node(T data_) :
data(std::move(data_))
{}
};
std::unique_ptr<node> head;
node* tail; // 使用标准指针而非智能指针是因为unique_ptr只能独占
public:
queue()
{}
queue(const queue& other) = delete;
queue& operator=(const queue& other) = delete;
std::shared_ptr<T> try_pop()
{
if (!head)
{
return std::shared_ptr<T>();
}
std::shared_ptr<T> const res(
std::make_shared<T>(std::move(head->data)));
std::unique_ptr<node> const old_head = std::move(head);
head = std::move(old_head->next);
return res;
}
void push(T new_value)
{
std::unique_ptr<node> p(new node(std::move(new_value)));
node* const new_tail = p.get();
if (tail)
{
tail->next = std::move(p);
}
else
{
head = std::move(p);
}
tail = new_tail;
}
};
上面的实现对单线程来说,没什么问题。但是如果你要使用细粒度的锁来对应多线程的话,就会出现一系列可能导致你出错的事情。该队列有两个数据成员head和tail,原则上你可以使用两个mutex分别对其进行保护,但这会造成一系列问题:
- 最明显的问题是push函数既可以修改head,也可以修改tail,所以它不得不锁住两个mutex;
- 最严重的问题是当队列只有一个元素时,如果两个线程分别使用push和
try_pop,由于此时head.get() == tail,所以tail->next和head->next指向的是同一个元素,所以需要同一个mutex进行保护,这还不如最开始的stack和queue呢。解决该问题的方法就是预先添加一个假的没有数据的node,这样就避免了这个问题:- 对于一个空队列,head和tail指向同一个假的node而非原来的nullptr;
- 当你添加一个元素时,更新tail,然后使其指向下一个假元素,这样head和tail将永远指向不同的元素,因此就不会造成对
head->next和tail->next的竞争了。
#pragma once
// 一个改善的简单的单线程队列实现
template<typename T>
class queue
{
private:
struct node
{
std::shared_ptr<T> data;
std::unique_ptr<node> next;
};
std::unique_ptr<node> head;
node* tail;
public:
queue() :
head(new node), tail(head.get())
{}
queue(const queue& other) = delete;
queue& operator=(const queue& other) = delete;
std::shared_ptr<T> try_pop()
{
if (head.get() == tail)
{
return std::shared_ptr<T>();
}
std::shared_ptr<T> const res(head->data);
std::unique_ptr<node> old_head = std::move(head);
head = std::move(old_head->next);
return res;
}
void push(T new_value)
{
std::shared_ptr<T> new_data(
std::make_shared<T>(std::move(new_value)));
std::unique_ptr<node> p(new node);
tail->data = new_data;
node* const new_tail = p.get();
tail->next = std::move(p);
tail = new_tail;
}
};
现在push只访问tail了,try_pop虽然同时访问head和tail,但是tail只是被用作初始比较,因此只需要短暂的lock。最大的增益就是try_pop和push永远不会在同一个node上操作了,所以你可以大胆的使用一个mutex保护head,一个mutex保护tail。
#pragma once
// 一个简单的使用细粒度锁的thread safe队列实现
#include <mutex>
template<typename T>
class threadsafe_queue
{
private:
struct node
{
std::shared_ptr<T> data;
std::unique_ptr<node> next;
};
std::mutex head_mutex;
std::unique_ptr<node> head;
std::mutex tail_mutex;
node* tail;
node* get_tail()
{
std::lock_guard<std::mutex> tail_lock(tail_mutex);
return tail;
}
std::unique_ptr<node> pop_head()
{
std::lock_guard<std::mutex> head_lock(head_mutex);
if (head.get() == get_tail())
{
return nullptr;
}
std::unique_ptr<node> old_head = std::move(head);
head = std::move(old_head->next);
return old_head;
}
public:
threadsafe_queue() :
head(new node), tail(head.get())
{}
threadsafe_queue(const threadsafe_queue& other) = delete;
threadsafe_queue& operator=(const threadsafe_queue& other) = delete;
std::shared_ptr<T> try_pop()
{
std::unique_ptr<node> old_head = pop_head();
return old_head ? old_head->data : std::shared_ptr<T>();
}
void push(T new_value)
{
std::shared_ptr<T> new_data(
std::make_shared<T>(std::move(new_value)));
std::unique_ptr<node> p(new node);
node* const new_tail = p.get();
std::lock_guard<std::mutex> tail_lock(tail_mutex);
tail->data = new_data;
tail->next = std::move(p);
tail = new_tail;
}
};
将get_tail放在head_mutex的lock范围内是为了保证得到的tail一定指向假元素,head也一定是当前的head。设想一种情况:将get_tail放置在head_mutex的lock范围外,如下所示:
std::unique_ptr<node> pop_head()
{
node* const old_tail = get_tail();
std::lock_guard<std::mutex> head_lock(head_mutex);
if (head.get() == old_tail)
{
return nullptr;
}
std::unique_ptr<node> old_head = std::move(head);
head = std::move(old_head->next);
return old_head;
}
当get_tail返回时,此时head可能已经发生了改变,在head和tail做比较时,也许tail已经被重新附了值,这样head不是你想要的head,tail也不是你想要的tail,就会造成跟预想结果不同的行为发生,将get_tail放在head_mutex的lock范围内就能完美的避免这种情况。
#pragma once
// 一个较完整的使用细粒度锁的thread safe队列
#include <condition_variable>
template<typename T>
class threadsafe_queue
{
private:
struct node
{
std::shared_ptr<T> data;
std::unique_ptr<node> next;
};
std::unique_ptr<node> head;
node* tail;
mutable std::mutex head_mutex;
mutable std::mutex tail_mutex;
std::condition_variable data_cond;
node* get_tail()
{
std::lock_guard<std::mutex> tail_lock(tail_mutex);
return tail;
}
std::unique_ptr<node> pop_head()
{
std::unique_ptr<node> old_head = std::move(head);
head = std::move(old_head->next);
return old_head;
}
std::unique_lock<std::mutex> wait_for_data()
{
std::unique_lock<std::mutex> head_lock(head_mutex);
data_cond.wait(head_lock, [&] {return head.get() != get_tail(); });
return std::move(head_lock);
}
std::unique_ptr<node> wait_pop_head()
{
std::unique_lock<std::mutex> head_lock(wait_for_data());
return pop_head();
}
std::unique_ptr<node> wait_pop_head(T& value)
{
std::unique_lock<std::mutex> head_lock(wait_for_data());
value = std::move(*head->data);
return pop_head();
}
std::unique_ptr<node> try_pop_head()
{
std::lock_guard<std::mutex> head_lock(head_mutex);
if (head.get() == get_tail())
{
return std::unique_ptr<node>();
}
return pop_head();
}
std::unique_ptr<node> try_pop_head(T& value)
{
std::lock_guard<std::mutex> head_lock(head_mutex);
if (head.get() == get_tail())
{
return std::unique_ptr<node>();
}
value = std::move(*head->data);
return pop_head();
}
public:
threadsafe_queue() :
head(new node), tail(head.get())
{}
threadsafe_queue(const threadsafe_queue& other) = delete;
threadsafe_queue& operator=(const threadsafe_queue& other) = delete;
void push(T new_value)
{
std::shared_ptr<T> new_data(
std::make_shared<T>(std::move(new_value)));
std::unique_ptr<node> p(new node);
{
std::lock_guard<std::mutex> tail_lock(tail_mutex);
tail->data = new_data;
node* const new_tail = p.get();
tail->next = std::move(p);
tail = new_tail;
}
data_cond.notify_one();
}
std::shared_ptr<T> wait_and_pop()
{
std::unique_ptr<node> const old_head = wait_pop_head();
return old_head->data;
}
void wait_and_pop(T& value)
{
std::unique_ptr<node> const old_head = wait_pop_head(value);
}
std::shared_ptr<T> try_pop()
{
std::unique_ptr<node> old_head = try_pop_head();
return old_head ? old_head->data : std::shared_ptr<T>();
}
bool try_pop(T& value)
{
std::unique_ptr<node> const old_head = try_pop_head(value);
return old_head != nullptr;
}
bool empty() const
{
std::lock_guard<std::mutex> head_lock(head_mutex);
return (head.get() == get_tail());
}
};
基于锁的复杂并发数据结构设计
stack和queue非常简单,它们的接口相对固定,并且它们也应用于比较特殊的场合。大多数数据结构支持各种各样的操作,原则上这能增大并发的可能性,但是也增大了数据保护的难度。
lookup table
查找表(lookup table)就是键值对(key-value)的集合,在标准库中,如果键与值相等就是set,不等就是map。
查询表的使用与栈和队列不同。栈和队列上,几乎每个操作都会对数据结构进行修改,不是添加一个元素,就是删除一个,而对于查询表来说,几乎不需要什么修改。和队列和栈一样,标准容器的接口不适合多线程进行并发访问,因为这些接口在设计的时候都存在固有的条件竞争,所以这些接口需要砍掉,以及重新修订。
并发访问时,std::map<>接口最大的问题在于——迭代器。当你在处理一个迭代器时,也许其它线程已经删除了该迭代器指向的元素。关于迭代器的多线程设计可以放到后面,现在我们先来看一些查找表(lookup table)的基本操作:
- 添加一个键值对;
- 对于一个给定的键值,修改与其关联的值;
- 删除一个键值和其关联的值;
- 对于一个给定的键值,获取其关联的所有值;
- 是否为空。
如果你坚持使用简单的线程安全规范的话,你也可以在每个成员函数中只使用一个mutex进行上锁保护,这样肯定是安全的。有一个潜在的问题是:当两个线程同时对一个单映射查找表(lookup table)添加相同的键值对时,只有先开始的线程会成功。一种办法就是将添加和修改放在同一个成员函数中去。
当要查找的键值不存在时,可以添加一个默认值。
mapped_type get_value(key_type const& key, mapped_type default_value);
你也可以返回一个std::pair<mapped_type,bool>,其中bool值指示该键值是否存在;或者你也可以返回一个智能指针,当其为nullptr时,表示该键值不存在。
一旦接口决定了,你就可以开始码代码了。使用单个mutex对每个成员函数上锁会浪费并发的可能性;一个选项是使用一个支持多线程读和单线程改的mutex,如boost::shared_mutex;但理想情况下,我们可以做得更好。
要想得到细粒度的锁,你必须小心查看数据结构的实现细节,而不能直接包装已存在的容器,如std::map<>。这边有三个常见的方式来实现关联容器:
- 二叉树,如红黑树;
- 已排序数组;
- 哈希表。
二叉树并不能提供太多扩展并发的机会,每个查找或修改都不得不从访问根节点开始,因此根节点需要被上锁;虽然这个锁在访问线程向树下移动时可以被释放,但并不比直接使用单个锁锁住整个数据结构好太多。
已排序数组更差,因为你不能提前知晓一个给定的数据在该数组中的位置,所以你需要对整个数组上锁。
剩下的就只有哈希表了。假设有一个固定数量的buckets(一个键值拥有一个bucket,其关联的所有值都放在该bucket中),一个键值所属的bucket纯粹是该键值的一个属性及哈希函数(Assuming a fixed number of buckets, which bucket a key belongs to is purely a property of the key and its hash function)。这意味着你可以安全的对每个bucket使用不同的锁。如果你仍然使用类似boost::shared_mutex的mutex,你就能将并发的机会增加N倍,其中N是bucket的数量(显然原来只能有一个线程在写,现在可以有N个了)。缺点就是你需要为键值(key)设计一个好的哈希函数(对于一个给定值,任何时候调用此函数都应该返回相同的结果,对于不等的对象几乎总是产生不同的结果),庆幸的是,C++标准库提供了std::hash<>模板,一些基本的类型如int,还有一些常用的标准库类型如std::string都提供了特例化,你可以直接拿来使用,对于自定义类型可以查看模板特例化自行特例化。
#pragma once
// 一个完成了基本功能的细粒度线程安全查找表
#include <vector>
#include <list>
#include <mutex>
#include <boost\thread\shared_mutex.hpp>
#include <boost\thread\locks.hpp>
template<typename Key, typename Value, typename Hash = std::hash<Key>>
class threadsafe_lookup_table
{
private:
class bucket_type
{
public:
typedef std::pair<Key, Value> bucket_value;
typedef std::list<bucket_value> bucket_data;
typedef typename bucket_data::iterator bucket_iterator;
bucket_data data;
mutable boost::shared_mutex mutex;
private:
bucket_iterator find_entry_for(Key const& key) const
{
return std::find_if(data.begin(), data.end(),
[&](bucket_value const& item)
{return item.first == key; });
}
public:
Value value_for(Key const& key, Value const& default_value) const
{
boost::shared_lock<boost::shared_mutex> lock(mutex);
bucket_iterator const found_entry = find_entry_for(key);
return (found_entry == data.end()) ?
default_value : found_entry->second;
}
void add_or_update_mapping(Key const& key, Value const& value)
{
std::unique_lock<boost::shared_mutex> lock(mutex);
bucket_iterator const found_entry = find_entry_for(key);
if (found_entry == data.end())
{
data.push_back(bucket_value(key, value));
}
else
{
found_entry->second = value;
}
}
void remove_mapping(Key const& key)
{
std::unique_lock<boost::shared_mutex> lock(mutex);
bucket_iterator const found_entry = find_entry_for(key);
if (found_entry != data.end())
{
data.erase(found_entry);
}
}
};
std::vector<std::unique_ptr<bucket_type> > buckets;
Hash hasher;
bucket_type& get_bucket(Key const& key) const
{
std::size_t const bucket_index = hasher(key) % buckets.size();
return *buckets[bucket_index];
}
public:
typedef Key key_type;
typedef Value mapped_type;
typedef Hash hash_type;
threadsafe_lookup_table(unsigned num_buckets = 19, Hash const& hasher_ = Hash()) :
buckets(num_buckets), hasher(hasher_)
{
for (unsigned i = 0; i<num_buckets; ++i)
{
buckets[i].reset(new bucket_type);
}
}
threadsafe_lookup_table(threadsafe_lookup_table const& other) = delete;
threadsafe_lookup_table& operator=(threadsafe_lookup_table const& other) = delete;
Value value_for(Key const& key, Value const& default_value = Value()) const
{
return get_bucket(key).value_for(key, default_value);
}
void add_or_update_mapping(Key const& key, Value const& value)
{
get_bucket(key).add_or_update_mapping(key, value);
}
void remove_mapping(Key const& key)
{
get_bucket(key).remove_mapping(key);
}
};
上面的示例函数不多,仔细看个十分钟左右应该能够看懂。仔细看完,你会发现,该代码其实是相当简单的,但是每个关键的地方都做了适当的数据保护。其中bucket数量的默认值是19,这个值是随便写的,但是哈希表在拥有质数个buckets的时候工作的最好;因为bucket的数量是固定的,所以get_bucket可以在无锁的状态下被调用,然后再通过bucket_type的成员函数进行适当的数据保护。
该示例是线程安全的,但是不是异常安全的呢?
- 首先,
value_for并不修改数据,它抛不抛出异常无关紧要; remove_mapping调用了erase,但erase保证不会抛出异常,所以是安全的;- 最后是
add_or_update_mapping,它的两个if分支都可能抛出异常:push_back如果抛出异常会将list保持在原有状态,所以是安全的;- 如果赋值运算符抛出异常,你可以祈祷它保持在原有状态,然而这不并影响整个数据结构,这完全是用户提供的类型的一个属性,你可以安全的留给用户来处理这件事。
在获取全部键值对快照的时候,需要锁住全部的buckets:
std::map<Key, Value> get_map() const
{
std::vector<std::unique_lock<boost::shared_mutex> > locks;
for (unsigned i = 0; i<buckets.size(); ++i)
{
locks.push_back(
std::unique_lock<boost::shared_mutex>(buckets[i]->mutex));
}
std::map<Key, Value> res;
for (unsigned i = 0; i<buckets.size(); ++i)
{
for (auto it = buckets[i]->data.begin();
it != buckets[i]->data.end();
++it)
{
res.insert(*it);
}
}
return res;
}
std::vector<Key> get_Key() const
{
std::vector<std::unique_lock<boost::shared_mutex> > locks;
for (unsigned i = 0; i<buckets.size(); ++i)
{
locks.push_back(
std::unique_lock<boost::shared_mutex>(buckets[i]->mutex));
}
std::vector<Key> res;
for (unsigned i = 0; i<buckets.size(); ++i)
{
for (auto it = buckets[i]->data.begin();
it != buckets[i]->data.end();
++it)
{
res.push_back(it->first);
}
}
return res;
}
在测试编译时,bucket_type的find_entry_for一直提示不能将const_iterator转换成iterator,发现其是const限定的,所以data是const的,故而data.begin()、data.end()返回的都是const_iterator,而函数要求返回的是iterator,由于后面的add_or_update_mapping和remove_mapping也调用了该函数,并且修改了其指向的数据,所以不能直接将bucket_iterator改为bucket_const_iterator,解决方案是重载该函数,一个const限定返回bucket_const_iterator,一个没有const限定,返回bucket_iterator,如下所示:
#pragma once
// 一个改善了的完成了基本功能的细粒度线程安全查找表
#include <vector>
#include <list>
#include <mutex>
#include <algorithm>
#include <boost\thread\shared_mutex.hpp>
#include <boost\thread\locks.hpp>
template<typename Key, typename Value, typename Hash = std::hash<Key>>
class threadsafe_lookup_table
{
private:
class bucket_type
{
typedef std::pair<Key, Value> bucket_value;
typedef std::list<bucket_value> bucket_data;
typedef typename bucket_data::iterator bucket_iterator;
typedef typename bucket_data::const_iterator bucket_const_iterator;
bucket_iterator find_entry_for(Key const& key)
{
return std::find_if(data.begin(), data.end(),
[&](bucket_value const& item) {return item.first == key; });
}
bucket_const_iterator find_entry_for(Key const& key) const
{
return std::find_if(data.begin(), data.end(),
[&](bucket_value const& item) {return item.first == key; });
}
public:
bucket_data data;
mutable boost::shared_mutex mutex;
Value value_for(Key const& key, Value const& default_value) const
{
boost::shared_lock<boost::shared_mutex> lock(mutex);
bucket_const_iterator found_entry = find_entry_for(key);
return (found_entry == data.end()) ?
default_value : found_entry->second;
}
void add_or_update_mapping(Key const& key, Value const& value)
{
std::unique_lock<boost::shared_mutex> lock(mutex);
bucket_iterator const found_entry = find_entry_for(key);
if (found_entry == data.end())
{
data.push_back(bucket_value(key, value));
}
else
{
found_entry->second = value;
}
}
void remove_mapping(Key const& key)
{
std::unique_lock<boost::shared_mutex> lock(mutex);
bucket_iterator const found_entry = find_entry_for(key);
if (found_entry != data.end())
{
data.erase(found_entry);
}
}
};
std::vector<std::unique_ptr<bucket_type> > buckets;
Hash hasher;
bucket_type& get_bucket(Key const& key) const
{
std::size_t const bucket_index = hasher(key) % buckets.size();
return *buckets[bucket_index];
}
public:
typedef Key key_type;
typedef Value mapped_type;
typedef Hash hash_type;
threadsafe_lookup_table(unsigned num_buckets = 19, Hash const& hasher_ = Hash()) :
buckets(num_buckets), hasher(hasher_)
{
for (unsigned i = 0; i<num_buckets; ++i)
{
buckets[i].reset(new bucket_type);
}
}
threadsafe_lookup_table(threadsafe_lookup_table const& other) = delete;
threadsafe_lookup_table& operator=(threadsafe_lookup_table const& other) = delete;
Value value_for(Key const& key, Value const& default_value = Value()) const
{
return get_bucket(key).value_for(key, default_value);
}
void add_or_update_mapping(Key const& key, Value const& value)
{
get_bucket(key).add_or_update_mapping(key, value);
}
void remove_mapping(Key const& key)
{
get_bucket(key).remove_mapping(key);
}
std::map<Key, Value> get_map() const
{
std::vector<std::unique_lock<boost::shared_mutex> > locks;
for (unsigned i = 0; i<buckets.size(); ++i)
{
locks.push_back(
std::unique_lock<boost::shared_mutex>(buckets[i]->mutex));
}
std::map<Key, Value> res;
for (unsigned i = 0; i<buckets.size(); ++i)
{
for (auto it = buckets[i]->data.begin();
it != buckets[i]->data.end();
++it)
{
res.insert(*it);
}
}
return res;
}
std::vector<Key> get_Key() const
{
std::vector<std::unique_lock<boost::shared_mutex> > locks;
for (unsigned i = 0; i<buckets.size(); ++i)
{
locks.push_back(
std::unique_lock<boost::shared_mutex>(buckets[i]->mutex));
}
std::vector<Key> res;
for (unsigned i = 0; i<buckets.size(); ++i)
{
for (auto it = buckets[i]->data.begin();
it != buckets[i]->data.end();
++it)
{
res.push_back(it->first);
}
}
return res;
}
};
测试代码如下:
#include <iostream>
#include <cstdlib>
#include <thread>
#include "myLookupTable.h"
threadsafe_lookup_table<int,int> g_lookup_table;
void add_data()
{
int loop_count = 10;
for (int i = 0; i < loop_count; ++i)
{
g_lookup_table.add_or_update_mapping(i, i);
}
}
void print_data()
{
int loop_count = 10;
for (int i = 0; i < loop_count; ++i)
{
std::cout << g_lookup_table.value_for(i, 0) << std::endl;
}
}
int main()
{
auto t1 = std::thread(add_data);
auto t2 = std::thread(print_data);
t1.join();
t2.join();
}
boost::thread的库需要编译,步骤如下:
- dos下进入到你下载的boost解压包文件夹,我的是
cd E:\boost_1_64_0\boost_1_64_0; cd tools\build;bootstrap.bat;- 复制生成的
bjam.exe到E:\boost_1_64_0\boost_1_64_0下; cd E:\boost_1_64_0\boost_1_64_0;- 根据你的vs版本(你可以先不添加库编译,vs会告诉你需要的库及你的vs版本号),
bjam --toolset=msvc-14.1 --with-thread stage; bjam --toolset=msvc-14.1 --with-date_time stage;- 最后需要的lib在
E:\boost_1_64_0\boost_1_64_0\stage\lib下; - 在debug/x86模式下添加库输入
libboost_date_time-vc141-mt-gd-1_64.lib和libboost_thread-vc141-mt-gd-1_64.lib即可。
测试结果(测试程序可能需要修改,用于确保print发生在add之后):
0
1
2
3
4
5
6
7
8
9
linked list
支持STL类型迭代器的基本问题是:这个迭代器必须持有这个容器内部数据结构的一些类型的引用。如果该容器能被另外的线程修改,该引用又必须保持在可用状态,那么就需要这个迭代器持有该数据结构一些部分的锁了。
让迭代器的生命周期完全脱离容器的控制是非常糟糕的,替代方案是使用像for_each一样的迭代函数来作为容器的一部分。这样就能让容器一直负责迭代和锁定,但是也违反了避免死锁的建议,因为为了让for_each做事,就必须调用在持有锁的情况下调用用户代码,这可能造成死锁;另外你还必须传递元素的引用到这个用户代码,这是非常危险的,因为用户代码可以将这个引用传递到外面,然后做什么事就脱离了掌控,继而可能造成条件竞争,你可以传递拷贝,但如果数据比较复杂,代价就会非常昂贵。但是你可以把这个问题交给用户,让他保证不会造成死锁,也不会存储引用,这是非常安全的,因为你知道他不会做一些淘气的事情。
剩下的就是你需要为你的list提供哪些操作了。上面的hash map包含了以下五个操作:
- 添加一个元素;
- 移除一个元素;
- 查找一个元素;
- 更新一个元素;
- 拷贝每个元素到另一个容器。
细粒度锁list的基本思想是:为每个node设置一个mutex,如果list太大,就会有好多好多mutex!这个方案的优点就是不同list部分的操作是真正并发的:每个操作持有它感兴趣的node的锁,然后离开时解锁。
#pragma once
// 一个线程安全的细粒度锁链表的简单实现
#include <mutex>
template<typename T>
class threadsafe_list
{
struct node
{
std::mutex m;
std::shared_ptr<T> data;
std::unique_ptr<node> next;
node() :
next()
{}
node(T const& value) :
data(std::make_shared<T>(value))
{}
};
node head;
public:
threadsafe_list()
{}
~threadsafe_list()
{
remove_if([](node const&) {return true; });
}
threadsafe_list(threadsafe_list const& other) = delete;
threadsafe_list& operator=(threadsafe_list const& other) = delete;
void push_front(T const& value)
{
std::unique_ptr<node> new_node(new node(value));
std::lock_guard<std::mutex> lk(head.m);
new_node->next = std::move(head.next);
head.next = std::move(new_node);
}
template<typename Function>
void for_each(Function f)
{
node* current = &head;
std::unique_lock<std::mutex> lk(head.m);
while (node* const next = current->next.get())
{
std::unique_lock<std::mutex> next_lk(next->m);
lk.unlock();
f(*next->data);
current = next;
lk = std::move(next_lk);
}
}
template<typename Predicate>
std::shared_ptr<T> find_first_if(Predicate p)
{
node* current = &head;
std::unique_lock<std::mutex> lk(head.m);
while (node* const next = current->next.get())
{
std::unique_lock<std::mutex> next_lk(next->m);
lk.unlock();
if (p(*next->data))
{
return next->data;
}
current = next;
lk = std::move(next_lk);
}
return std::shared_ptr<T>();
}
template<typename Predicate>
void remove_if(Predicate p)
{
node* current = &head;
std::unique_lock<std::mutex> lk(head.m);
while (node* const next = current->next.get())
{
std::unique_lock<std::mutex> next_lk(next->m);
if (p(*next->data))
{
std::unique_ptr<node> old_next = std::move(current->next);
current->next = std::move(next->next);
next_lk.unlock();
}
else
{
lk.unlock();
current = next;
lk = std::move(next_lk);
}
}
}
};
由于所有锁都是从head开始,按顺序进行lock的,所以不会有deadlock的危险;在remove_if函数中,如果删除的node正在被其他线程使用,就会造成条件竞争,但是由于该函数在删除的时候并没有unlock上一个node,所以正在删除的node是不可能被访问的;还是在remove_if函数中,下面的删除操作不能被替换为current->next.reset(next->next.release()),因为next = current->next.get(),如果先将current->next释放,那么next就是被删除的指针,继续使用会造成未定义行为,先将其转移到一个局部变量,然后将下一个node的指向赋给上一个node.next,最后该局部变量在生命周期结束时会自动释放。
std::unique_ptr<node> old_next = std::move(current->next);
current->next = std::move(next->next);
测试程序:
#include <iostream>
#include <cstdlib>
#include <thread>
#include "myLinkedList.h"
threadsafe_list<int> g_linked_lsit;
void add_data()
{
int loop_count = 10;
for (int i = 0; i < loop_count; ++i)
{
g_linked_lsit.push_front(i);
}
}
void print_data()
{
g_linked_lsit.for_each(
[](const int& i)
{std::cout << i << std::ends; });
}
int main()
{
auto t1 = std::thread(add_data);
auto t2 = std::thread(print_data);
t1.join();
t2.join();
}
测试结果:
9 8 7 6 5 4 3 2 1 0